
Key Points
-
The reasons for conducting a systematic review
-
The advantages and disadvantages of a meta-analysis
-
The calculation and evaluation of the effect of interest in a meta-analysis
-
An assessment of the compatibility of the trials in a meta-analysis
-
A description of some plots used in meta-analysis
Key Points
Further statistics in dentistry:
-
1
Research designs 1
-
2
Research designs 2
-
3
Clinical trials 1
-
4
Clinical trials 2
-
5
Diagnostic tests for oral conditions
-
6
Multiple linear regression
-
7
Repeated measures
-
8
Systematic reviews and meta-analyses
-
9
Bayesian statistics
-
10
Sherlock Holmes, evidence and evidence-based dentistry
Abstract
A systematic review of research evidence is an efficient approach to integrating existing information, invariably a multiplicity of published articles, with a view to establishing whether the scientific findings are consistent. If so, it may be possible to draw conclusions and make recommendations about treatment regimens or observed effects which have greater credence than those obtained from individual studies. The systematic review relies on a specified checklist which determines which articles should be included in the review, and how each should be critically appraised to provide relevant information relating to the focus of the review.
Similar content being viewed by others



Systematic reviews
The report of a systematic review is somewhat like that of a research paper; it contains a clear description of the aims, and the material and methods used by the reviewer. The alternative haphazard non-systematic review has no defined rules concerning the process of digesting the mass of information, and is open to abuse.
A systematic review serves various purposes:
-
It reduces a large amount of information to a manageable size. This information can be assimilated quickly by healthcare providers, researchers and policy makers. At the initial stage, the systematic review distinguishes between those studies that are essentially unsound and those that provide useful and scientifically worthwhile results in relation to the question of interest.
-
By combining the results from various studies which may have been conducted in slightly varying circumstances (eg using different definitions of disease or patient eligibility criteria), it may be possible to determine from the systematic review whether the results are consistent from study to study, and to generalise the results. Furthermore, a systematic review may offer the opportunity to explain any inconsistencies.
-
It is usually cheaper and quicker to conduct a systematic review than to embark on a new study.
-
It may reduce the delay between research discoveries and the implementation of new effective treatment strategies.
-
The systematic review combines information from individual studies so that its overall sample size is greater than that of any one study, and this leads to an increase in the power of the investigation. Thus, the systematic review has a greater chance of eliciting significant treatment effects, which is particularly helpful if the prevalence of the condition is low or if the effect of interest is small.
-
The systematic review has an increased sample size compared with any individual study so the estimates of the effects of interest are obtained with increased precision.
-
A systematic review limits bias and improves the reliability and accuracy of recommendations because of its formalised and thorough method of investigation.
The Cochrane Collaboration (www.update-software.com/ccweb/cochrane/general.htm) is an international network of individuals and institutions which prepares systematic reviews of randomised controlled studies and of observational evidence. It helps to promote the development of systematic reviews by setting explicit standards for systematic reviews. It provides a framework within which scientists of like interests can collaborate, and through its publication, the Cochrane Database of Systematic Reviews, allows electronic access to the latest detailed and highly structured reports on subjects of interest.
Meta-analysis
Meta-analysis
A meta-analysis integrates the quantitative findings from separate but similar studies and provides a numerical estimate of the overall effect of interest
A special form of systematic review is a meta-analysis (sometimes called an overview); this is a statistical approach to combining the results from separate but similar studies to provide an overall quantitative summary of the effect of interest. A meta-analysis is thus a statistical analysis of a collection of statistical analyses from individual studies. Full details of the theory of meta-analysis may be obtained in Hedges and Olkin (1985).1 In addition, a paper by Song et al.(1997)2 provides a useful discussion of how to handle discrepancies in recommendations arising from different meta-analyses of what appear to be the same research question.
In principle, a meta-analysis proffers the advantages of increased power, and increased precision of its estimates, when compared with a single study. In practice, the meta-analysis is open to criticism, essentially on four grounds (Glass et al., 1981):3
-
1
Because journals rarely publish studies in which the findings are non-significant, published research is biased in favour of significant results. A trial with a significant result is sometimes called a positive trial; a negative trial is one in which a clinically significant effect is essentially ruled out. This publication bias leads to biased meta-analysis results unless the meta-analyst makes a serious attempt to identify and use the results in books, dissertations, unpublished papers presented at professional meetings or located in retrieval systems for unpublished papers (such as SIGLE produced by the European Association for Grey Literature), etc.
-
2
The studies included in the meta-analysis may differ in respect of features such as design, outcome measure, measuring technique, definition of variables and subjects, and duration of follow-up. Such clinical heterogeneity needs to be explored carefully as it may affect the overall conclusions and the clinical implications of the review. Generally, a meta-analysis of clinical trials is restricted to include only those trials that are randomised. Additional requirements of blind or objective assessment of response, ideally with analysis by intention-to-treat and complete follow-up, are sometimes imposed (Peto, 1987).4 Such trials are less likely to lead to biased results than those which do not possess these attributes.
-
3
The studies included in the meta-analysis may vary in their quality, and it has been shown (Jahad, 1996)5 that a meta-analysis which comprises studies of high quality, as opposed to poor quality, tends to be less enthusiastic about an intervention. However, it can be argued that poorly designed or 'bad' studies should be included in the meta-analysis because of the inclusiveness of the method and the subjective nature of the considerations which might lead to their exclusion. The problem of including both 'good' and 'bad' studies can be handled empirically by conducting separate analyses for groups of studies of similar quality, and examining whether the results differ for poorly and well designed studies. Sometimes, the results from all the studies are combined by assigning weights to the studies according to their relative quality, but this approach can be criticised on grounds of the arbitrariness of the assignment.
-
4
The results included in the meta-analysis may not be independent. This situation arises when a multivariate study provides more than one test of significance relevant to the hypothesis that the meta-analysis is examining. Also, non-independence of the results may arise when the studies are conducted by the same investigator at different times, or by different investigators who have communicated with each other and modified their studies on the basis of earlier results. Furthermore, some trials are published more than once.
Example
Meta-analyses in dentistry are not very common. The example used in this paper, a meta-analysis by van Rijkom et al. (1998),6 can be criticised but is, nevertheless, thorough and accessible. The authors used a meta-analysis to estimate the overall caries inhibiting effect of fluoride gels applied to the permanent teeth of children aged 6 to 15 years. Each of the 19 studies included in the analysis, referenced by study number at the end of this paper, was obtained from a MEDLINE search of the published literature of English and German studies. All these studies satisfied various selection inclusion and exclusion criteria, and their follow-up periods were between 1.5 and 3 years (median 3 years). In particular, each of the chosen studies was a randomised controlled trial in which the effect of the fluoride gel treatment was compared with no treatment or placebo treatment. In fact, some of the 19 studies were independent substudies of a larger study which had been split into two to reflect differences in general fluoride regimen. The inhibiting effect of the treatment was expressed for each study by the prevented fraction (PF); this was calculated as the difference in the incidence between the decayed, missing and filled surfaces (DMFS) in the control group (lc) and the incidence in the experimental group (le), divided by that in the control group [ie PF = (lc – le)/lc]. The absolute difference between the incidences in the two groups was standardized (ie divided by lc) since the PF was assumed to be less sensitive to experimental circumstances, such as the age range of the study population and the duration of the study, than (lc – le).
The effect of interest in a meta-analysis
Explaining the effect of interest
Suppose that the meta-analysis comprises k studies, and that θi denotes the value of an appropriate measure of the effect of interest in the ith study. In a clinical trial, this will usually be the effect of the experimental treatment relative to the control treatment. If the outcome variable is quantitative, θi is typically the difference between the experimental and control treatment means in the population or some standardized version of this difference. If the outcome is binary, for example 'success' or 'failure', θi is often the logarithm of the odds ratio or relative risk. In the fluoride gel example, the effect of interest is the prevented fraction (PF), expressed as a percentage.
There are two approaches to combining the information in a meta-analysis. The parametric approach is usually adopted; this assumes that the effect of interest in each study is Normally distributed. Note that both the difference between the means and its standardized difference are Normally distributed for Normally distributed data; similarly, the logarithm of the relative risk, equal to the difference in the logarithms of the two risks, is approximately Normally distributed. The PF in this example is assumed to be approximated Normally distributed. The parametric approach focuses on combining the results from the k studies, estimating the overall effect of interest, with its confidence interval, testing its significance and interpreting these results. Occasionally, a non-parametric approach is used which makes no distributional assumptions about the effect of interest. However, the non-parametric methods often require the raw data from each study, which can limit their use, and they are not described here.
Displaying the effect of interest
Initially, it is helpful to display the quantitative results from each study both in tabular and diagrammatic form. The table includes the relevant information on each trial; for example, the sample size, baseline patient characteristics, information on inclusion criteria and withdrawal rates, and the effects of interest, such as the odds ratio. Table 1 summarises some of the more important features of the selected studies in the fluoride gel example.
The most usual pictorial representation (Fig. 1) is sometimes called a 'forest plot'. It shows the estimated effect of interest (in the fluoride gel example it is the PF but might, in other circumstances, be the standardized difference in means or the odds ratio) for each of the separate studies in the meta-analysis. The confidence intervals for the true effect in each case, as well as the overall estimated effect (and related confidence interval) from the pooled data from all the studies, are also indicated. An explanation of the method used to calculate the overall estimated effect is given in the section entitled 'calculating the effect of interest'. A vertical line, known as the 'line of no effect', is sometimes drawn in the diagram. It represents equal effectiveness of the treatments (for example, it would correspond to a value of zero for PF or a difference in means, or unity if the effect of interest were the odds ratio). In the fluoride gel example, only five of the confidence intervals for the true PFs cross the line of no effect, whereas twelve of the confidence intervals are to the right of it; this suggests that fluoride gel is an effective inhibitor of caries.

The shaded area shows the 95% confidence interval for the pooled PF.6
It is possible to get some idea of whether the estimates of the effects from the different studies are compatible by 'eye-balling' the forest plot. If the confidence intervals of the effects overlap, then the trials are likely to be compatible, whereas if there is no overlap, then they are incompatible. The confidence intervals in Fig. 1 show considerable overlap, suggesting that the results of the different studies are likely to be compatible. However, it should be noted that the estimated PFs show substantial variation, so this conclusion should be viewed with caution.
Checking for compatibility between the trials
Heterogeneity between studies
-
Statistical heterogeneity exists when the quantitative results from the studies in a meta-analysis exhibit considerable variation.
-
Clinical heterogeneity exists when the studies differ in features such as the design, outcome measure, definition of variables and subjects, etc.
A more formal approach to determining incompatibility is to perform a statistical test, described in detail in the section entitled 'Testing for homogeneity'. If, on the basis of the test result, the observed effects are more disperse than would be expected on the basis of chance alone, statistical heterogeneity is said to be present, ie the estimated effects exhibit considerable variation and are incompatible. Statistical heterogeneity may be caused by clinical heterogeneity, methodological differences or it may be related to unknown trial characteristics. The presence of statistical heterogeneity is indicated if the test of statistical homogeneity (homogeneity implies that the effects are equal) is significant. If the test is not significant, this does not imply that there must be statistical homogeneity. A non-significant result implies only that there is no evidence to reject the null hypothesis of homogeneity, and not that there is evidence to accept it. It should be pointed out that the test of statistical homogeneity has low power and, therefore, may fail to produce a statistically significant result unless there is marked heterogeneity. Whether or not the test is significant, it is important to provide an estimate of the extent to which there is statistical heterogeneity. Then, if this estimate indicates that there might be substantial statistical heterogeneity, the aspects of clinical heterogeneity which may be causing it should be investigated.
Calculating the effect of interest
The overall estimate of effect is usually taken as a weighted average of the estimates from the k individual studies in the meta-analysis. Thus the estimate of the overall effect is:

where  i is the estimated effect and wi the weight of the ith study, and the sums extend over all k studies. Usually the weights are chosen to be inversely related to the variances of the estimated effects and this is approximately the same as choosing weights which are proportional to the sample size, so that the larger studies are given more weight than the smaller ones.
i is the estimated effect and wi the weight of the ith study, and the sums extend over all k studies. Usually the weights are chosen to be inversely related to the variances of the estimated effects and this is approximately the same as choosing weights which are proportional to the sample size, so that the larger studies are given more weight than the smaller ones.
-
A fixed-effects estimation method can be used if there is no evidence of statistical heterogeneity and/or if the meta-analysis comprises only a small number of studies. This approach assumes that the separate studies are the only ones that are of interest, and that the underlying true effect in each study is the same and equal to θ, ie θ1 = θ2 = ... = θk = θ. The variance of the estimated effect in each study comprises only the random variation in that study. When estimating the assumed common effect, θ, the weight attached to each θiis the reciprocal of its variance, so that more weight is given to the more precise estimate (ie that with a narrower confidence interval).
-
If statistical heterogeneity is believed to be present, the random-effects estimation method may be appropriate. This approach assumes that the k separate studies are a random sample from a larger population of studies, and there is a population effect of interest, θ, about which the effects of the individual studies vary. Then
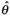 is an estimate of θ which is now the mean of the effects of interest obtained from all the studies in the population. As in the fixed-effects method, the weight for the ith study using the random-effects method is chosen to be the reciprocal of the variance of the estimated effect for that study. However, unlike the fixed-effects method, the random-effects method incorporates both the random variation within the study and the heterogeneity between the different studies into this variance. It produces a wider confidence interval for the overall estimate than the fixed-effects method, as would be expected from an estimate that reflects the heterogeneity of the estimates. It is important to remember that if there is statistical heterogeneity, caution must be adopted when interpreting the overall estimate of effect, however it is derived, and the reasons for the heterogeneity should be investigated.
is an estimate of θ which is now the mean of the effects of interest obtained from all the studies in the population. As in the fixed-effects method, the weight for the ith study using the random-effects method is chosen to be the reciprocal of the variance of the estimated effect for that study. However, unlike the fixed-effects method, the random-effects method incorporates both the random variation within the study and the heterogeneity between the different studies into this variance. It produces a wider confidence interval for the overall estimate than the fixed-effects method, as would be expected from an estimate that reflects the heterogeneity of the estimates. It is important to remember that if there is statistical heterogeneity, caution must be adopted when interpreting the overall estimate of effect, however it is derived, and the reasons for the heterogeneity should be investigated.
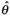 is an estimate of θ which is now the mean of the effects of interest obtained from all the studies in the population. As in the fixed-effects method, the weight for the ith study using the random-effects method is chosen to be the reciprocal of the variance of the estimated effect for that study. However, unlike the fixed-effects method, the random-effects method incorporates both the random variation within the study and the heterogeneity between the different studies into this variance. It produces a wider confidence interval for the overall estimate than the fixed-effects method, as would be expected from an estimate that reflects the heterogeneity of the estimates. It is important to remember that if there is statistical heterogeneity, caution must be adopted when interpreting the overall estimate of effect, however it is derived, and the reasons for the heterogeneity should be investigated.
is an estimate of θ which is now the mean of the effects of interest obtained from all the studies in the population. As in the fixed-effects method, the weight for the ith study using the random-effects method is chosen to be the reciprocal of the variance of the estimated effect for that study. However, unlike the fixed-effects method, the random-effects method incorporates both the random variation within the study and the heterogeneity between the different studies into this variance. It produces a wider confidence interval for the overall estimate than the fixed-effects method, as would be expected from an estimate that reflects the heterogeneity of the estimates. It is important to remember that if there is statistical heterogeneity, caution must be adopted when interpreting the overall estimate of effect, however it is derived, and the reasons for the heterogeneity should be investigated.Note that for both the fixed-effects and random-effects approaches, an approximate 95% confidence interval for the overall estimate of effect, θ, is given by  ± 1.96√(1/Σ wi). The wi is the reciprocal of the variance of the estimated effect in the ith study. It is a measure of the random variation within the study for the fixed-effects approach, but includes the variation between the k estimated effects as well for the random-effects approach.
± 1.96√(1/Σ wi). The wi is the reciprocal of the variance of the estimated effect in the ith study. It is a measure of the random variation within the study for the fixed-effects approach, but includes the variation between the k estimated effects as well for the random-effects approach.
The authors in the fluoride gel example used two approaches to investigate heterogeneity. Firstly, they believed that the large overlap in the confidence intervals in the forest plot was an indication that there was no evidence of statistical heterogeneity. However, although there was considerable overlap in the confidence intervals, the estimates from the different studies showed substantial variation. Secondly, they used a multiple regression analysis to determine whether there were factors influencing the caries-inhibiting effect of fluoride gel application. This analysis showed no significant influence of the covariables that were thought could be relevant, namely, 'application frequency', 'application methods' (tray/brush), 'baseline caries prevalence' and 'general fluoride regimen'. Thus, they concluded that all studies could be regarded as equally effective, and the overall effect could be estimated using a fixed effects model. The weight for each study was chosen to be the inverse of the variance of the prevented fraction, PF; this gave an estimated overall PF of 22%. The 95% confidence interval for the true PF was 18% to 25%, the shaded area in Fig. 1; this excludes zero and suggests that fluoride gel was an effective inhibitor of caries in children of this age.
Hypothesis tests in meta-analysis
There are two hypothesis tests that are of crucial importance in a meta-analysis, one which tests for homogeneity of the effects of interest and the other which tests the significance of the overall treatment effect.
Testing for homogeneity
The test of the null hypothesis that the studies are homogenous with respect to their effects of interest should be performed initially, rather than relying solely on the subjective opinion obtained from the forest plot. The test of this hypothesis, sometimes called that of 'combinability', is usually based on the magnitude of the test statistic

which is assumed to follow a chi-squared distribution with (k–1) degrees of freedom. As homogeneity is assumed under the null hypothesis in this test, the fixed-effects and the random-effects approaches are not distinguished, and the weight, wi, is the same as that used in the fixed-effects approach, i.e. it is the reciprocal of the variance of the effect in the ith study (i = 1, 2, 3, . . ., k), where that variance is a measure only of the random variation within the study.
It is interesting to note that, even though the confidence intervals for the PF's from the separate studies overlap (Fig. 1), the chi-squared test of homogeneity in the fluoride gel example gives a result which is marginally significant at the 5% level. This, together with the view that the different studies have estimated PFs which show considerable variation, should perhaps be an indication that combining the estimates of PF is questionable and that the overall estimate of the PF should be interpreted with caution.
In addition to the overall test which investigates heterogeneity (in fact, it tests homogeneity), it is possible to test for funnel plot asymmetrywhich assesses bias. Details may be obtained from Eggar et al., (1997).7 A funnel plot (Fig. 2) is a scatter plot of the sample size against the treatment effect estimate generated in an individual study. The sample size can be replaced by the precision of the estimated effect. Since the precision of the estimated treatment effect increases as the sample size of the component study increases, the results from small studies would be expected to show a wide scatter at the bottom of the graph, with the spread decreasing (narrowing to produce a funnel effect) at the top of the graph for the larger studies. The funnel plot will often be skewed and asymmetrical if bias is present, as demonstrated in Fig. 2. The lower left corner of the funnel is somewhat empty (ie lacking publications), indicating that some studies on small sample sizes with small effects are probably missing. The effect of this publication bias on the overall PF, however, is likely to be marginal, because the weight of such unpublished low-power studies is small. It is possible to measure the degree of asymmetry in a funnel plot, but the approach is of limited value if only a few trials are included (remembering that the unit of analysis is the randomised trial and not its patients).

Funnel plot of the sample size for each study plotted against the estimated prevented fraction, PF (%) for the 19 studies included in the meta-analysis
Testing the treatment effect
The null hypothesis that the true effect of interest is zero (ie Ho: θ1 = θ2 = ... = θk= 0 in the fixed-effects method, or Ho: θ= 0 in the random-effects method) is tested using the test statistic:

which follows the chi-squared distribution with one degree of freedom. Each wi is the reciprocal of the variance of the estimated effect of the ith study. In the fixed-effects approach, this variance is a measure only of the random variation within the study; in the random-effects method, the variance comprises both the random variation within the study and the variation between the estimated effects in the k studies. The test for the overall PF in the fluoride gel example gives a highly significant result (P< 0.001) indicating that the overall effect, estimated by a PF of 22% (95% confidence interval equal to 18% to 25%), is significantly different from zero. This implies that the fluoride gel is an effective inhibitor of caries in children of this age. Note that, as observed previously, zero lies outside the 95% confidence interval for the overall PF, as expected if the test result is significant.

References
Hedges LV, Olkin I Statistical Methods for Meta-analysis Academic Press: New York 1985
Song F, Landes DP, Glenny A-M, Sheldon TA . Prophylactic removal of impacted third molars: an assessment of published reviews Br Dent J 1997; 182: 339–346
Glass G, McGaw B, Smith MJ Meta-analysis in Social Research Beverly Hills CA: Sage 1981
Peto R . Why do we need systematic overviews of randomised trials? Stat Med 1987; 6: 233–240
Jahad AR, McQuay HJ . Meta analyses to evaluate analgesic interventions: a systematic qualitative review of their methodology J Clin Epidemiol 1996; 49: 235–243
van Rijkom HM, Truin GJ, van't Hof MA . A meta-analysis of clinical studies on the caries-inhibiting effect of fluoride gel treatment Caries Res 1998; 32: 83–92
Eggar M, Davey Smith G, Schneider M, Minder C . Bias in meta-analysis detected by a simple, graphical test Br Med J 1997; 315: 629–634
Acknowledgements
The authors would like to thank Dr James Lewsey for his comments on earlier drafts of the manuscript.
Author information
Authors and Affiliations
Corresponding author
Additional information
Refereed paper
Rights and permissions
About this article
Cite this article
Petrie, A., Bulman, J. & Osborn, J. Further statistics in dentistry Part 8: Systematic reviews and meta-analyses. Br Dent J 194, 73–78 (2003). https://doi.org/10.1038/sj.bdj.4809877
Published:
Issue Date:
DOI: https://doi.org/10.1038/sj.bdj.4809877
This article is cited by
-
The risk of hepatic pseudoaneurysm after liver trauma in relation to the severity of liver injury: a meta-analysis and meta-regression analysis
Langenbeck's Archives of Surgery (2023)
-
Meta-analysis of the outcomes of Trans Rectus Sheath Extra-Peritoneal Procedure (TREPP) for inguinal hernia
Hernia (2022)
-
Efficacy of near infrared dental lasers on dentinal hypersensitivity: a meta-analysis of randomized controlled clinical trials
Lasers in Medical Science (2022)
-
C-reactive protein and fracture risk: an updated systematic review and meta-analysis of cohort studies through the use of both frequentist and Bayesian approaches
Osteoporosis International (2021)
-
Does the institutionalization influence elderly’s quality of life? A systematic review and meta–analysis
BMC Geriatrics (2020)
