Automated Pulmonary Nodule Detection System in Computed Tomography Images: A Hierarchical Block Classification Approach

Abstract
:1. Introduction
2. Proposed Method

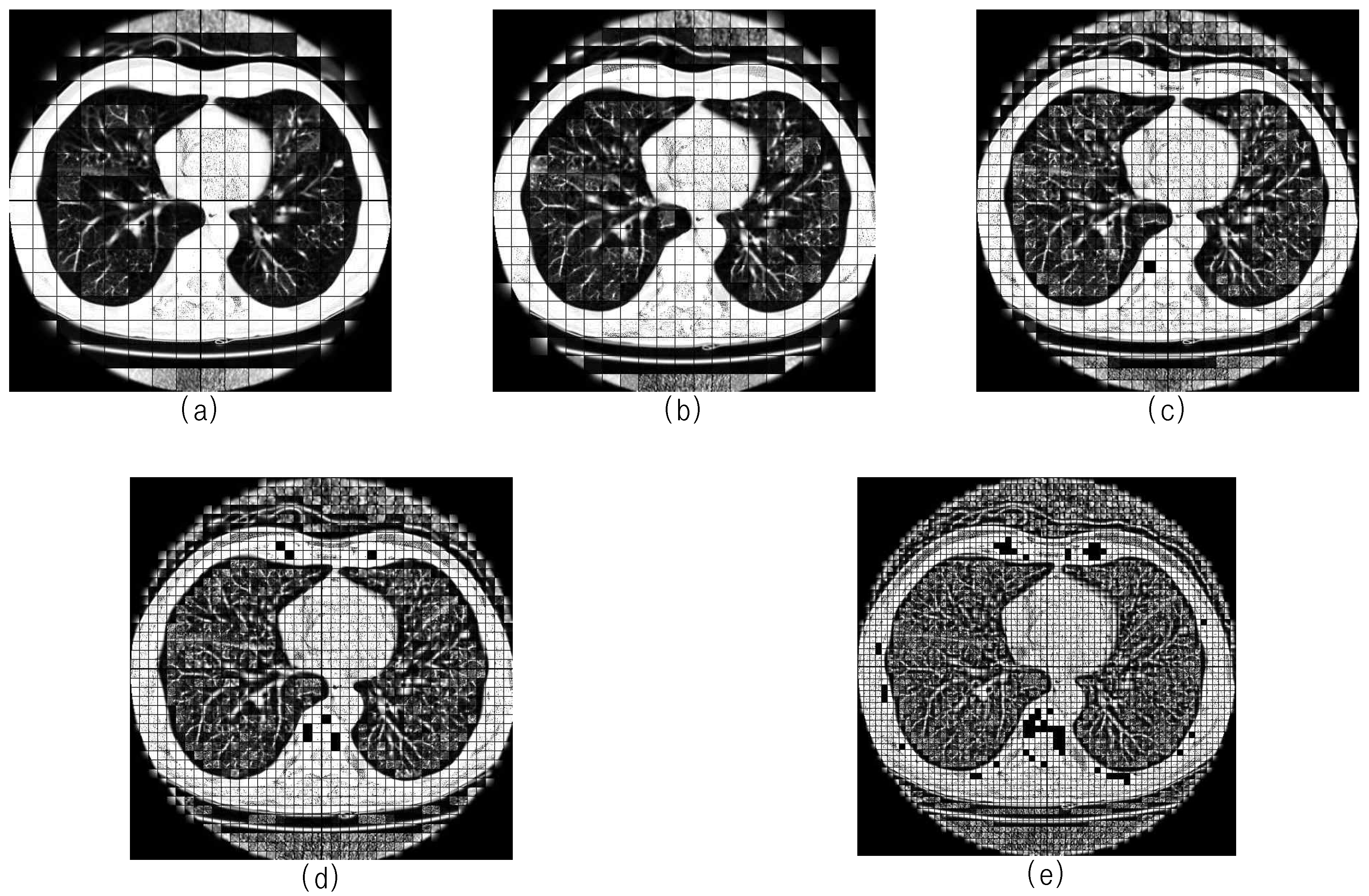
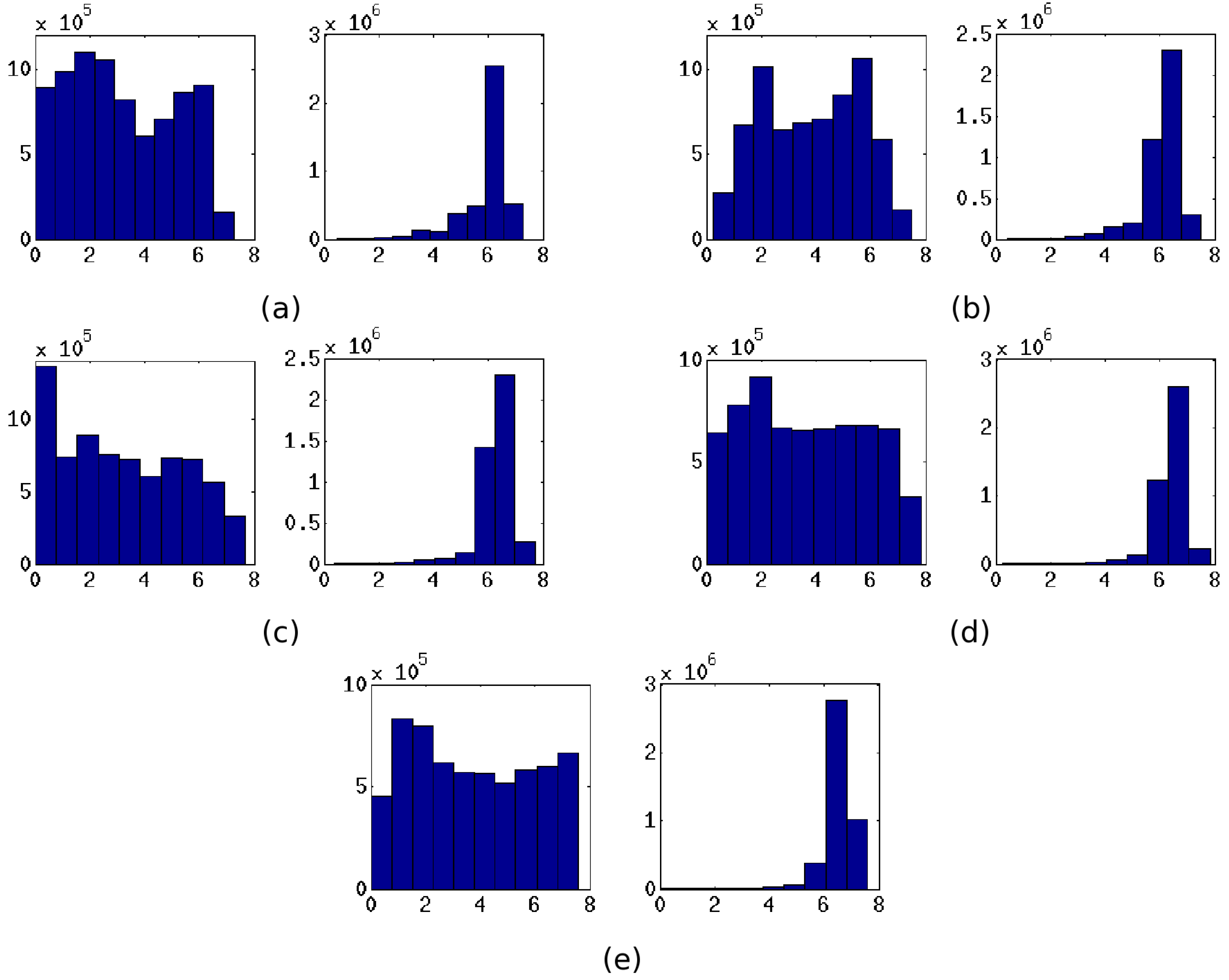
3. Three-Dimensional Block Image Selection Based on Entropy Analysis


4. Nodule Candidates Selection Based on Block Analysis
4.1. Block Image Enhancement

4.2. Block Segmentation and Location Adjustment

5. Nodule Detection
5.1. Feature Extraction

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Index | Feature | Description |
|---|---|---|
| 2-D geometric feature vectors | ||
| Area | Number of pixels in the median slice of the segmented object O | |
| Diameter | Maximum bounding box length of | |
| Circularity | Area divided by squared perimeter of the circumscribed circle where | |
| 3-D geometric feature vectors | ||
| Volume | Total count of voxels in the segmented object O | |
| Compactness | Volume divided by volume of the circumscribed sphere | |
| Elongation | Ratio between maximum principal axis length and minimum principal axis length | |
| 2-D texture feature vectors | ||
| Mean | Mean intensity of the median slice of nodule candidates block image | |
| Variance | Variance intensity of | |
| Skewness | Skewness intensity of | |
| Kurtosis | Kurtosis intensity of | |
| Eigenvalues | Eight largest eigenvalues of | |
5.2. Support Vector Machine Classifier
5.2.1. Classifier Training
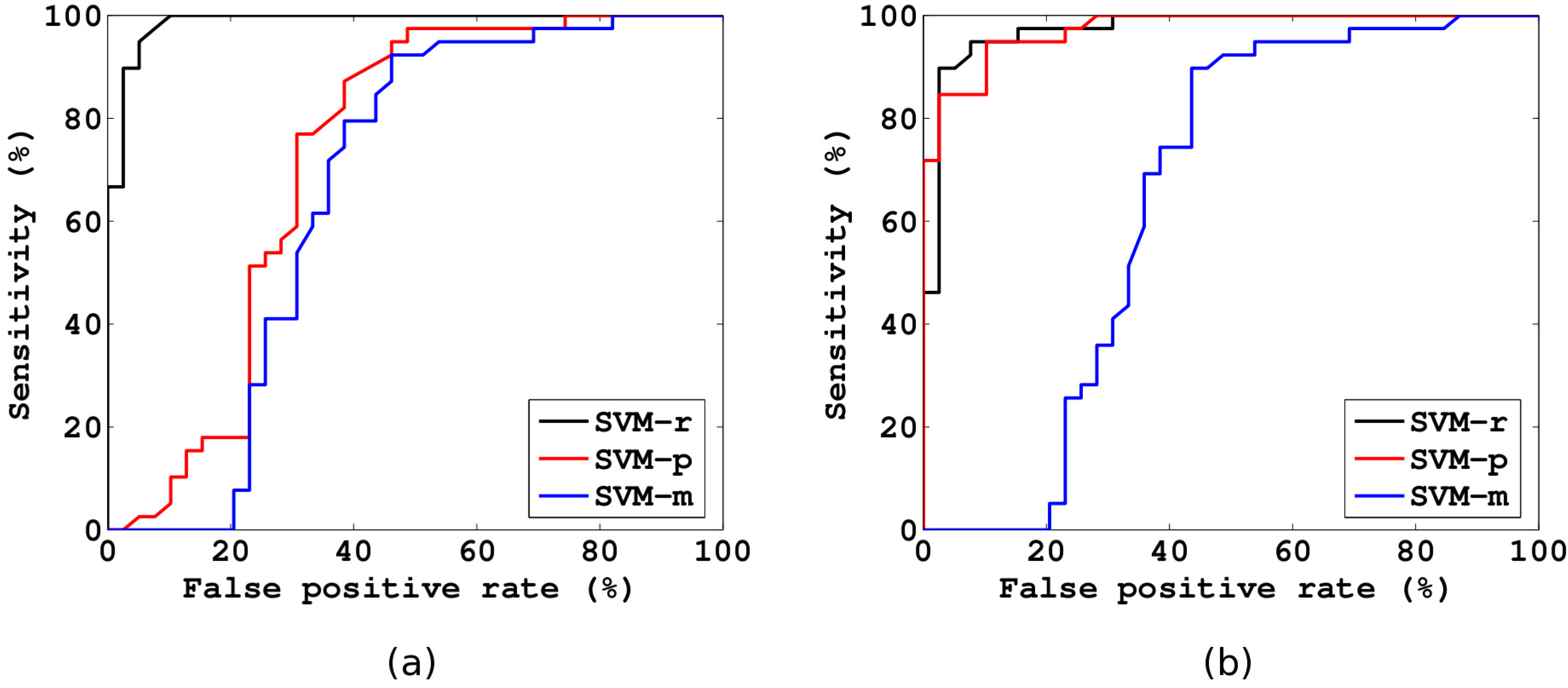
5.2.2. Nodule Detection and Classifier Validation
6. Experimental Results and Discussion
| k | p | AUC | MCC | NPV | Accuracy | Sensitivity | Specificity |
|---|---|---|---|---|---|---|---|
| 5 | 0.25 | 0.9738 | 0.8312 | 88.20% | 91.52% | 87.16% | 95.88% |
| 7 | 0.25 | 0.9784 | 0.8816 | 91.61% | 93.97% | 91.02% | 96.92% |
| 10 | 0.25 | 0.9736 | 0.8548 | 90.16% | 92.43% | 88.97% | 95.88% |
| p | AUC | MCC | NPV | Accuracy | Sensitivity | Specificity | |
|---|---|---|---|---|---|---|---|
| SVM-r | 0.1 | 0.9727 | 0.7322 | 76.96% | 84.72% | 69.44% | 100.00% |
| 0.125 | 0.9746 | 0.7990 | 82.65% | 88.96% | 78.70% | 99.23% | |
| 0.25 | 0.9784 | 0.8816 | 91.61% | 93.97% | 91.02% | 96.92% | |
| 0.5 | 0.9754 | 0.8545 | 91.77% | 92.82% | 91.54% | 94.10% | |
| 1 | 0.9712 | 0.8364 | 91.63% | 91.79% | 91.53% | 92.05% | |
| 2 | 0.9673 | 0.8443 | 93.01% | 92.30% | 93.08% | 91.53% | |
| SVM-p | 0.1 | 0.4660 | -0.1486 | 16.14% | 47.40% | 0.00% | 94.81% |
| 0.125 | 0.4632 | -0.1095 | 17.07% | 44.81% | 0.26% | 89.35% | |
| 0.25 | 0.6876 | 0.4019 | 81.78% | 68.26% | 86.13% | 50.39% | |
| 0.5 | 0.9462 | 0.8058 | 92.02% | 89.85% | 91.52% | 88.18% | |
| 1 | 0.9463 | 0.8188 | 92.77% | 90.74% | 92.78% | 88.69% | |
| 2 | 0.9646 | 0.8514 | 92.17% | 92.29% | 91.25% | 93.32% | |
| SVM-m | 0.1 | 0.8706 | 0.6524 | 85.72% | 82.55% | 86.91% | 78.19% |
| 0.125 | 0.7051 | 0.4154 | 75.49% | 69.71% | 78.46% | 60.95% | |
| 0.25 | 0.5706 | 0.2300 | 64.25% | 60.68% | 68.69% | 52.68% | |
| 0.5 | 0.5469 | 0.1911 | 62.02% | 59.02% | 66.63% | 51.41% | |
| 1 | 0.5420 | 0.1749 | 60.93% | 58.11% | 66.11% | 50.12% | |
| 2 | 0.5527 | 0.1673 | 60.56% | 57.60% | 65.85% | 49.36% |

| p | AUC | MCC | NPV | Accuracy | Specificity | Sensitivity | false positives/scan |
| Nodule Candidates Detection | 97.35% | 60.21 | |||||
| 0.1 | 0.9931 | 0.9594 | 99.11% | 95.89% | 99.62% | 92.67% | 0.23 |
| 0.125 | 0.9934 | 0.9509 | 99.35% | 96.92% | 99.11% | 93.95% | 0.54 |
| 0.25 | 0.9929 | 0.8785 | 99.59% | 97.61% | 96.23% | 95.28% | 2.27 |
| 0.5 | 0.9835 | 0.8082 | 99.10% | 95.15% | 93.93% | 92.85% | 3.65 |
| 1 | 0.9727 | 0.7602 | 98.66% | 92.98% | 92.33% | 90.63% | 4.62 |
| 2 | 0.9584 | 0.7101 | 98.58% | 92.41% | 89.74% | 90.45% | 6.18 |

| CAD systems | Nodule size | Sensitivity | Avg. false positives /scan |
|---|---|---|---|
| Dehmeshki et al.(2007) [7] | 3-20 | 90% | 14.6 |
| SuarezCuenca et al.(2009) [8] | 4-27 | 80% | 7.7 |
| Opfer and Wiemeker(2007)[28] | ≥4 | 74% | 4 |
| Messay et al.(2010) [5] | 3-30 | 82.66% | 3 |
| Choi et al.(2012) [6] | 3-30 | 94.1% | 5.45 |
| Proposed method | 3-30 | 95.28% | 2.27 |
7. Conclusions
Acknowledgements
References
- Jemal, A.; Siegel, R.; Ward, E.; Hao, Y.; Xu, J.; Thun, M.J. Cancer statistics, 2009. CA: Cancer J. Clin. 2009, 59, 225–249. [Google Scholar] [CrossRef] [PubMed]
- Bach, P.; Mirkin, J.; Oliver, T.; Azzoli, C.; Berry, D.; Brawley, O.; Byers, T.; Colditz, G.; Gould, M.; Jett, J.; et al. Benefits and harms of CT screening for lung cancer. Context 2012, 307, 2418–2429. [Google Scholar] [CrossRef] [PubMed]
- Armato, S.G.; Li, F.; Giger, M.L.; MacMahon, H.; Sone, S.; Doi, K. Lung cancer: Performance of automated lung nodule detection applied to cancers missed in a CT screening program. Radiology 2002, 225, 685–692. [Google Scholar] [CrossRef] [PubMed]
- Sluimer, I.; Schilham, A.; Prokop, M.; van Ginneken, B. Computer analysis of computed tomography scans of the lung: A survey. IEEE Trans. Med. Imaging 2006, 25, 385–405. [Google Scholar] [CrossRef] [PubMed]
- Messay, T.; Hardie, R.; Rogers, S. A new computationally efficient CAD system for pulmonary nodule detection in CT imagery. Med. Image Anal. 2010, 14, 390–406. [Google Scholar] [CrossRef] [PubMed]
- Choi, W.J.; Choi, T.S. Genetic programming-based feature transform and classification for the automatic detection of pulmonary nodules on computed tomography images. Inf. Sci. 2012, 212, 57–78. [Google Scholar] [CrossRef]
- Dehmeshki, J.; Ye, X.; Lin, X.; Valdivieso, M.; Amin, H. Automated detection of lung nodules in CT images using shape-based genetic algorithm. Comput. Med. Imaging Gr. 2007, 31, 408–417. [Google Scholar] [CrossRef] [PubMed]
- Suárez-Cuenca, J.; Tahoces, P.; Souto, M.; Lado, M.; Remy-Jardin, M.; Remy, J.; José Vidal, J. Application of the iris filter for automatic detection of pulmonary nodules on computed tomography images. Comput. Biol. Med. 2009, 39, 921–933. [Google Scholar] [CrossRef] [PubMed]
- Ye, X.; Lin, X.; Dehmeshki, J.; Slabaugh, G.; Beddoe, G. Shape-based computer-aided detection of lung nodules in thoracic CT images. IEEE Trans. Biomed. Eng. 2009, 56, 1810–1820. [Google Scholar] [PubMed]
- Sluimer, I.; Prokop, M.; van Ginneken, B. Toward automated segmentation of the pathological lung in CT. IEEE Trans. Med. Imaging 2005, 24, 1025–1038. [Google Scholar] [CrossRef] [PubMed]
- De Nunzio, G.; Tommasi, E.; Agrusti, A.; Cataldo, R.; De Mitri, I.; Favetta, M.; Maglio, S.; Massafra, A.; Quarta, M.; Torsello, M.; et al. Automatic lung segmentation in CT images with accurate handling of the hilar region. J. Digital Imaging 2011, 24, 11–27. [Google Scholar] [CrossRef] [PubMed]
- Ali, A.; Farag, A. Automatic lung segmentation of volumetric low-dose CT scans using graph cuts. Adv. Visual Comput. 2008, 5358, 258–267. [Google Scholar]
- Van Rikxoort, E.; de Hoop, B.; Viergever, M.; Prokop, M.; van Ginneken, B. Automatic lung segmentation from thoracic computed tomography scans using a hybrid approach with error detection. Med. Phys. 2009, 36, 2934. [Google Scholar] [CrossRef] [PubMed]
- Paik, D.; Beaulieu, C.; Rubin, G.; Acar, B.; Jeffrey, R.; Yee, J.; Dey, J.; Napel, S. Surface normal overlap: A computer-aided detection algorithm with application to colonic polyps and lung nodules in helical CT. IEEE Trans. Med. Imaging 2004, 23, 661–675. [Google Scholar] [CrossRef] [PubMed]
- Armato, S.G.; Giger, M.L.; Moran, C.J.; Blackburn, J.T.; Doi, K.; MacMahon, H. Computerized detection of pulmonary nodules on CT scans. Radiographics 1999, 19, 1303–1311. [Google Scholar] [CrossRef] [PubMed]
- Pu, J.; Paik, D.; Meng, X.; Roos, J.; Rubin, G. Shape break-and-repair strategy and its application to automated medical image segmentation. IEEE Trans. Visualization Comput. Gr. 2011, 17, 115–124. [Google Scholar]
- Kubota, T.; Jerebko, A.; Dewan, M.; Salganicoff, M.; Krishnan, A. Segmentation of pulmonary nodules of various densities with morphological approaches and convexity models. Med. Image Anal. 2011, 15, 133–154. [Google Scholar] [CrossRef] [PubMed]
- Lee, S.; Kouzani, A.; Hu, E. Random forest based lung nodule classification aided by clustering. Comput. Med. Imaging Gr. 2010, 34, 535–542. [Google Scholar] [CrossRef] [PubMed]
- Niemeijer, M.; Loog, M.; Abramoff, M.; Viergever, M.; Prokop, M.; van Ginneken, B. On combining computer-aided detection systems. IEEE Trans. Med. Imaging 2011, 30, 215–223. [Google Scholar] [CrossRef] [PubMed]
- Reeves, A.P.; Biancardi, A.M.; Apanasovich, T.V.; Meyer, C.R.; MacMahon, H.; van Beek, E.J.; Kazerooni, E.A.; Yankelevitz, D.; McNitt-Gray, M.F.; McLennan, G.; et al. The Lung Image Database Consortium (LIDC): A comparison of different size metrics for pulmonary nodule measurements. Acad. Radiol. 2007, 14, 1475–1485. [Google Scholar] [CrossRef] [PubMed]
- Shannon, C.; Weaver, W.; Blahut, R.; Hajek, B. The Mathematical Theory of Communication; University of Illinois Press: Urbana, IL, USA, 1949; Volume 117. [Google Scholar]
- Haralick, R.; Shanmugam, K.; Dinstein, I. Textural features for image classification. IEEE Trans. Syst. Man Cybern. 1973, SMC-3, 610–621. [Google Scholar] [CrossRef]
- Murtagh, F.; Contreras, P.; Starck, J.L. Scale-based gaussian coverings: Combining intra and inter mixture models in image segmentation. Entropy 2009, 11, 513–528. [Google Scholar] [CrossRef]
- Mendrik, A.; Vonken, E.J.; Rutten, A.; Viergever, M.; van Ginneken, B. Noise reduction in computed tomography scans using 3-D anisotropic hybrid diffusion with continuous switch. IEEE Trans. Med. Imaging 2009, 28, 1585–1594. [Google Scholar] [CrossRef] [PubMed]
- Weickert, J.; Scharr, H. A scheme for coherence-enhancing diffusion filtering with optimized rotation invariance. J. Visual Commun. Image Represent. 2002, 13, 103–118. [Google Scholar] [CrossRef]
- Hu, S.; Hoffman, E.; Reinhardt, J. Automatic lung segmentation for accurate quantitation of volumetric X-ray CT images. IEEE Trans. Med. Imaging 2001, 20, 490–498. [Google Scholar] [CrossRef] [PubMed]
- Boser, B.; Guyon, I.; Vapnik, V. A Training Algorithm for Optimal Margin Classifiers. In Proceedings of the Fifth Annual Workshop on Computational Learning Theory, Pittsburgh, PA, USA, 27–29 July 1992; ACM: New York, NY, USA, 1992; pp. 144–152. [Google Scholar]
- Opfer, R.; Wiemker, R. Performance Analysis for Computer-Aided Lung Nodule Detection on LIDC Data. In Proceedings of SPIE Medical Imaging, San Diego, CA, USA, 17 February 2007; Volume 6515, p. 65151C.
© 2013 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution license (http://creativecommons.org/licenses/by/3.0/).
Share and Cite
Choi, W.-J.; Choi, T.-S. Automated Pulmonary Nodule Detection System in Computed Tomography Images: A Hierarchical Block Classification Approach. Entropy 2013, 15, 507-523. https://doi.org/10.3390/e15020507
Choi W-J, Choi T-S. Automated Pulmonary Nodule Detection System in Computed Tomography Images: A Hierarchical Block Classification Approach. Entropy. 2013; 15(2):507-523. https://doi.org/10.3390/e15020507
Chicago/Turabian StyleChoi, Wook-Jin, and Tae-Sun Choi. 2013. "Automated Pulmonary Nodule Detection System in Computed Tomography Images: A Hierarchical Block Classification Approach" Entropy 15, no. 2: 507-523. https://doi.org/10.3390/e15020507