
Abstract
Automatic segmentation of the liver and its lesion is an important step towards deriving quantitative biomarkers for accurate clinical diagnosis and computer-aided decision support systems. This paper presents a method to automatically segment liver and lesions in CT abdomen images using cascaded fully convolutional neural networks (CFCNs) and dense 3D conditional random fields (CRFs). We train and cascade two FCNs for a combined segmentation of the liver and its lesions. In the first step, we train a FCN to segment the liver as ROI input for a second FCN. The second FCN solely segments lesions from the predicted liver ROIs of step 1. We refine the segmentations of the CFCN using a dense 3D CRF that accounts for both spatial coherence and appearance. CFCN models were trained in a 2-fold cross-validation on the abdominal CT dataset 3DIRCAD comprising 15 hepatic tumor volumes. Our results show that CFCN-based semantic liver and lesion segmentation achieves Dice scores over \(94\,\%\) for liver with computation times below 100 s per volume. We experimentally demonstrate the robustness of the proposed method as a decision support system with a high accuracy and speed for usage in daily clinical routine.
You have full access to this open access chapter, Download conference paper PDF
Similar content being viewed by others

Keywords
1 Introduction
Anomalies in the shape and texture of the liver and visible lesions in CT are important biomarkers for disease progression in primary and secondary hepatic tumor disease [9]. In clinical routine, manual or semi-manual techniques are applied. These, however, are subjective, operator-dependent and very time-consuming. In order to improve the productivity of radiologists, computer-aided methods have been developed in the past, but the challenges in automatic segmentation of combined liver and lesion remain, such as low-contrast between liver and lesion, different types of contrast levels (hyper-/hypo-intense tumors), abnormalities in tissues (metastasectomie), size and varying amount of lesions.
Nevertheless, several interactive and automatic methods have been developed to segment the liver and liver lesions in CT volumes. In 2007 and 2008, two Grand Challenges benchmarks on liver and liver lesion segmentation have been conducted [4, 9]. Methods presented at the challenges were mostly based on statistical shape models. Furthermore, grey level and texture based methods have been developed [9]. Recent work on liver and lesion segmentation employs graph cut and level set techniques [15–17], sigmoid edge modeling [5] or manifold and machine learning [6, 11]. However, these methods are not widely applied in clinics, due to their speed and robustness on heterogeneous, low-contrast real-life CT data. Hence, interactive methods were still developed [1, 7] to overcome these weaknesses, which yet involve user interaction.
Deep Convolutional Neural Networks CNN have gained new attention in the scientific community for solving computer vision tasks such as object recognition, classification and segmentation [14, 18], often out-competing state-of-the art methods. Most importantly, CNN methods have proven to be highly robust to varying image appearance, which motivates us to apply them to fully automatic liver and lesions segmentation in CT volumes.
Semantic image segmentation methods based on fully convolutional neural networks FCN were developed in [18], with impressive results in natural image segmentation competitions [3, 24]. Likewise, new segmentation methods based on CNN and FCNs were developed for medical image analysis, with highly competitive results compared to state-of-the-art. [8, 12, 19–21, 23].
In this work, we demonstrate the combined automatic segmentation of the liver and its lesions in low-contrast heterogeneous CT volumes. Our contributions are three-fold. First, we train and apply fully convolutional CNN on CT volumes of the liver for the first time, demonstrating the adaptability to challenging segmentation of hepatic liver lesions. Second, we propose to use a cascaded fully convolutional neural network (CFCN) on CT slices, which segments liver and lesions sequentially, leading to significantly higher segmentation quality. Third, we propose to combine the cascaded CNN in 2D with a 3D dense conditional random field approach (3DCRF) as a post-processing step, to achieve higher segmentation accuracy while preserving low computational cost and memory consumption. In the following sections, we will describe our proposed pipeline (Sect. 2.2) including CFCN (Sect. 2.3) and 3D CRF (Sect. 2.4), illustrate experiments on the 3DIRCADb dataset (Sect. 2) and summarize the results (Sect. 4).
2 Methods
In the following section, we denote the 3D image volume as I, the total number of voxels as N and the set of possible labels as \(\mathcal {\mathcal {L}}= \{0,1,\ldots ,l\}\). For each voxel i, we define a variable \(x_i \in \mathcal {\mathcal {L}}\) that denotes the assigned label. The probability of a voxel i belonging to label k given the image I is described by \(P(x_i=k \vert I)\) and will be modelled by the FCN. In our particular study, we use \(\mathcal {\mathcal {L}}= \{0,1,2\}\) for background, liver and lesion, respectively.

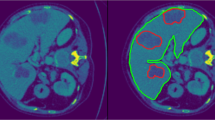
Automatic liver and lesion segmentation with cascaded fully convolutional networks (CFCN) and dense conditional random fields (CRF). Green depicts correctly predicted liver segmentation, yellow for liver false negative and false positive pixels (all wrong predictions), blue shows correctly predicted lesion segmentation and red lesion false negative and false positive pixels (all wrong predictions). In the first row, the false positive lesion prediction in B of a single UNet as proposed by [20] were eliminated in C by CFCN as a result of restricting lesion segmentation to the liver ROI region. In the second row, applying the 3DCRF to CFCN in F increases both liver and lesion segmentation accuracy further, resulting in a lesion Dice score of 82.3 %.
2.1 3DIRCADb Dataset
For clinical routine usage, methods and algorithms have to be developed, trained and evaluated on heterogeneous real-life data. Therefore, we evaluated our proposed method on the 3DIRCADb datasetFootnote 1[22]. In comparison to the grand challenge datasets, the 3DIRCADb dataset offers a higher variety and complexity of livers and its lesions and is publicly available. The 3DIRCADb dataset includes 20 venous phase enhanced CT volumes from various European hospitals with different CT scanners. For our study, we trained and evaluated our models using the 15 volumes containing hepatic tumors in the liver with 2-fold cross validation. The analyzed CT volumes differ substantially in the level of contrast-enhancement, size and number of tumor lesions (1 to 42). We assessed the performance of our proposed method using the quality metrics introduced in the grand challenges for liver and lesion segmentation by [4, 9].
2.2 Data Preparation, Processing and Pipeline
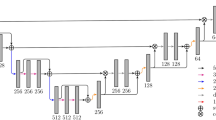
Pre-processing was carried out in a slice-wise fashion. First, the Hounsfield unit values were windowed in the range \([-100,400]\) to exclude irrelevant organs and objects, then we increased contrast through histogram equalization. As in [20], to teach the network the desired invariance properties, we augmented the data by applying translation, rotation and addition of gaussian noise. Thereby resulting in an increased training dataset of 22,693 image slices, which were used to train two cascaded FCNs based on the UNet architecture [20]. The predicted segmentations are then refined using dense 3D Conditional Random Fields. The entire pipeline is depicted in Fig. 2.

Overview of the proposed image segmentation pipeline. In the training phase, the CT volumes are trained after pre-processing and data augmentation in a cascaded fully convolutional neural network (CFCN). To gain the final segmented volume, the test volume is fed-forward in the (CFCN) and refined afterwards using a 3D conditional random field 3DCRF.
2.3 Cascaded Fully Convolutional Neural Networks (CFCN)
We used the UNet architecture [20] to compute the soft label probability maps \(P(x_i \vert I)\). The UNet architecture enables accurate pixel-wise prediction by combining spatial and contextual information in a network architecture comprising 19 convolutional layers. In our method, we trained one network to segment the liver in abdomen slices (step 1), and another network to segment the lesions, given an image of the liver (step 2). The segmented liver from step 1 is cropped and resampled to the required input size for the cascaded UNet in step 2, which further segments the lesions.
The motivation behind the cascade approach is that it has been shown that UNets and other forms of CNNs learn a hierarchical representation of the provided data. The stacked layers of convolutional filters are tailored towards the desired classification in a data-driven manner, as opposed to designing hand-crafted features for separation of different tissue types. By cascading two UNets, we ensure that the UNet in step 1 learns filters that are specific for the detection and segmentation of the liver from an overall abdominal CT scan, while the UNet in step 2 arranges a set of filters for separation of lesions from the liver tissue. Furthermore, the liver ROI helps in reducing false positives for lesions.
A crucial step in training FCNs is appropriate class balancing according to the pixel-wise frequency of each class in the data. In contrast to [18], we observed that training the network to segment small structures such as lesions is not possible without class balancing, due to the high class imbalance. Therefore we introduced an additional weighting factor \(\omega ^{class}\) in the cross entropy loss function L of the FCN.
\(P_i\) denotes the probability of voxel i belonging to the foreground, \(\hat{P_i}\) represents the ground truth. We chose \(\omega ^{class}_i\) to be \(\frac{1}{\vert {\text {Pixels of Class } x_i=k} \vert }\).
The CFCNs were trained on a NVIDIA Titan X GPU, using the deep learning framework caffe [10], at a learning rate of 0.001, a momentum of 0.8 and a weight decay of 0.0005.
2.4 3D Conditional Random Field (3DCRF)
Volumetric FCN implementation with 3D convolutions is strongly limited by GPU hardware and available VRAM [19]. In addition, the anisotropic resolution of medical volumes (e.g. 0.57−0.8 mm in xy and 1.25−4 mm in z voxel dimension in 3DIRCADb) complicates the training of discriminative 3D filters. Instead, to capitalise on the locality information across slices within the dataset, we utilize 3D dense conditional random fields CRFs as proposed by [13]. To account for 3D information, we consider all slice-wise predictions of the FCN together in the CRF applied to the entire volume at once.
We formulate the final label assignment given the soft predictions (probability maps) from the FCN as maximum a posteriori (MAP) inference in a dense CRF, allowing us to consider both spatial coherence and appearance.
We specify the dense CRF following [13] on the complete graph \(\mathcal {G}=(\mathcal {V}, \mathcal {E})\) with vertices \(i \in \mathcal {V}\) for each voxel in the image and edges \(e_{ij} \in \mathcal {E}= \lbrace (i, j) \forall i, j \in \mathcal {V}\mathrm {s.t.}\,\, i < j \rbrace \) between all vertices. The variable vector \(\mathbf {x}\in \mathcal {\mathcal {L}}^N\) describes the label of each vertex \(i \in \mathcal {V}\). The energy function that induces the according Gibbs distribution is then given as:
where \(\phi _i(x_i) = -\log P\left( x_i \vert I \right) \) are the unary potentials that are derived from the FCNs probabilistic output, \(P\left( x_i \vert I \right) \). \(\phi _{ij}(x_i,x_j)\) are the pairwise potentials, which we set to:
where \(\mu (x_i,x_j) = \mathbf {1}(x_i \ne x_j)\) is the Potts function, \(\vert p_i - p_j \vert \) is the spatial distance between voxels i and j and \(\vert I_i - I_j \vert \) is their intensity difference in the original image. The influence of the pairwise terms can be adjusted with their weights \(w_{\mathrm {pos}}\) and \(w_{\mathrm {bil}}\) and their effective range is tuned with the kernel widths \(\sigma _{\mathrm {pos}}, \sigma _{\mathrm {bil}}\) and \(\sigma _{\mathrm {int}}\).
We estimate the best labelling \(\mathbf {x}^* = {{\mathrm{arg\,min}}}_{\mathbf {x}\in \mathcal {\mathcal {L}}^N} E(\mathbf {x})\) using the efficient mean field approximation algorithm of [13]. The weights and kernels of the CRF were chosen using a random search algorithm.
3 Results and Discussion
The qualitative results of the automatic segmentation are presented in Fig. 1. The complex and heterogeneous structure of the liver and all lesions were detected in the shown images. The cascaded FCN approach yielded an enhancement for lesions with respect to segmentation accuracy compared to a single FCN as can be seen in Fig. 1. In general, we observe significantFootnote 2 additional improvements for slice-wise Dice overlaps of liver segmentations, from mean Dice \(93.1\,\%\) to \(94.3\,\%\) after applying the 3D dense CRF.
Quantitative results of the proposed method are reported in Table 1. The CFCN achieves higher scores as the single FCN architecture. Applying the 3D CRF improved the segmentations results of calculated metrics further. The runtime per slice in the CFCN is \(2\cdot 0.2\,s=0.4\) s without and 0.8 s with CRF.
In comparison to state-of-the-art, such as [2, 5, 15, 16], we presented a framework, which is capable of a combined segmentation of the liver and its lesion.
4 Conclusion
Cascaded FCNs and dense 3D CRFs trained on CT volumes are suitable for automatic localization and combined volumetric segmentation of the liver and its lesions. Our proposed method competes with state-of-the-art. We provide our trained models under open-source license allowing fine-tuning for other medical applications in CT dataFootnote 3. Additionally, we introduced and evaluated dense 3D CRF as a post-processing step for deep learning-based medical image analysis. Furthermore, and in contrast to prior work such as [5, 15, 16], our proposed method could be generalized to segment multiple organs in medical data using multiple cascaded FCNs. All in all, heterogeneous CT volumes from different scanners and protocols as present in the 3DIRCADb dataset and in clinical trials can be segmented in under 100 s each with the proposed approach. We conclude that CFCNs and dense 3D CRFs are promising tools for automatic analysis of liver and its lesions in clinical routine.
Notes
- 1.
The dataset is available on http://ircad.fr/research/3d-ircadb-01.
- 2.
Two-sided paired t-test with p-value \(< 4 \cdot 10^{-19}\).
- 3.
Trained models are available at https://github.com/IBBM/Cascaded-FCN.
References
Ben-Cohen, A., et al.: Automated method for detection and segmentation of liver metastatic lesions in follow-up CT examinations. J. Med. Imaging 3 (2015)
Chartrand, G., et al.: Semi-automated liver CT segmentation using Laplacian meshes. In: ISBI, pp. 641–644. IEEE (2014)
Chen, L.C., et al.: Semantic image segmentation with deep convolutional nets and fully connected CRFs. In: ICLR (2015)
Deng, X., Du, G.: Editorial: 3D segmentation in the clinic: a grand challenge ii-liver tumor segmentation. In: MICCAI Workshop (2008)
Foruzan, A.H., Chen, Y.W.: Improved segmentation of low-contrast lesions using sigmoid edge model. Int. J. Comput. Assist. Radiol. Surg., 1–17 (2015)
Freiman, M., Cooper, O., Lischinski, D., Joskowicz, L.: Liver tumors segmentation from cta images using voxels classification and affinity constraint propagation. Int. J. Comput. Assist. Radiol. Surg. 6(2), 247–255 (2011)
Häme, Y., Pollari, M.: Semi-automatic liver tumor segmentation with hidden markov measure field model and non-parametric distribution estimation. Med. Image Anal. 16(1), 140–149 (2012)
Havaei, M., et al.: Brain tumor segmentation with deep neural networks. Med. Image Anal. (2016)
Heimann, T., et al.: Comparison and evaluation of methods for liver segmentation from ct datasets. IEEE Trans. Med. Imag. 28(8), 1251–1265 (2009)
Jia, Y., Shelhamer, E., Donahue, J., Karayev, S., Long, J., Girshick, R., Guadarrama, S., Darrell, T.: Caffe: convolutional architecture for fast feature embedding. In: Proceeding ACM International Conference Multimedia, pp. 675–678. ACM (2014)
Kadoury, S., Vorontsov, E., Tang, A.: Metastatic liver tumour segmentation from discriminant grassmannian manifolds. Phys. Med. Biol. 60(16), 6459 (2015)
Kamnitsas, K., et. al.: Efficient multi-scale 3D CNN with fully connected CRF for accurate brain lesion segmentation (2016). arXiv preprint arXiv:1603.05959
Krähenbühl, P., Koltun, V.: Efficient inference in fully connected CRFs with gaussian edge potentials. In: NIPS, pp. 109–117 (2011)
Krizhevsky, A., Sutskever, I., Hinton, G.E.: Imagenet classification with deep convolutional neural networks. In: NIPS, pp. 1097–1105 (2012)
Li, C., Wang, X., Eberl, S., Fulham, M., Yin, Y., Chen, J., Feng, D.D.: A likelihood and local constraint level set model for liver tumor segmentation from ct volumes. IEEE Trans. Biomed. Eng. 60(10), 2967–2977 (2013)
Li, G., Chen, X., Shi, F., Zhu, W., Tian, J., Xiang, D.: Automatic liver segmentation based on shape constraints and deformable graph cut in ct images. IEEE Trans. Image Process. 24(12), 5315–5329 (2015)
Linguraru, M.G., Richbourg, W.J., Liu, J., Watt, J.M., Pamulapati, V., Wang, S., Summers, R.M.: Tumor burden analysis on computed tomography by automated liver and tumor segmentation. IEEE Trans. Med. Imag. 31(10), 1965–1976 (2012)
Long, J., Shelhamer, E., Darrell, T.: Fully convolutional networks for semantic segmentation. In: CVPR (2015)
Prasoon, A., Petersen, K., Igel, C., Lauze, F., Dam, E., Nielsen, M.: Deep feature learning for knee cartilage segmentation using a triplanar convolutional neural network. In: Mori, K., Sakuma, I., Sato, Y., Barillot, C., Navab, N. (eds.) MICCAI 2013. LNCS, vol. 8150, pp. 246–253. Springer, Heidelberg (2013). doi:10.1007/978-3-642-40763-5_31
Ronneberger, O., Fischer, P., Brox, T.: U-Net: convolutional networks for biomedical image segmentation. In: Navab, N., Hornegger, J., Wells, W.M., Frangi, A.F. (eds.) MICCAI 2015. LNCS, vol. 9351, pp. 234–241. Springer, Heidelberg (2015). doi:10.1007/978-3-319-24574-4_28
Roth, H.R., Lu, L., Farag, A., Shin, H.-C., Liu, J., Turkbey, E.B., Summers, R.M.: DeepOrgan: multi-level deep convolutional networks for automated pancreas segmentation. In: Navab, N., Hornegger, J., Wells, W.M., Frangi, A.F. (eds.) MICCAI 2015. LNCS, vol. 9349, pp. 556–564. Springer, Heidelberg (2015). doi:10.1007/978-3-319-24553-9_68
Soler, L., et al.: 3D image reconstruction for comparison of algorithm database: a patient-specific anatomical and medical image database (2012)
Wang, J., MacKenzie, J.D., Ramachandran, R., Chen, D.Z.: Detection of Glands and Villi by collaboration of domain knowledge and deep learning. In: Navab, N., Hornegger, J., Wells, W.M., Frangi, A.F. (eds.) MICCAI 2015. LNCS, vol. 9350, pp. 20–27. Springer, Heidelberg (2015). doi:10.1007/978-3-319-24571-3_3
Zheng, S., Jayasumana, S., Romera-Paredes, B., Vineet, V., Su, Z., Du, D., Huang, C., Torr, P.: Conditional random fields as recurrent neural networks. In: ICCV (2015)
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2016 Springer International Publishing AG
About this paper
Cite this paper
Christ, P.F. et al. (2016). Automatic Liver and Lesion Segmentation in CT Using Cascaded Fully Convolutional Neural Networks and 3D Conditional Random Fields. In: Ourselin, S., Joskowicz, L., Sabuncu, M., Unal, G., Wells, W. (eds) Medical Image Computing and Computer-Assisted Intervention – MICCAI 2016. MICCAI 2016. Lecture Notes in Computer Science(), vol 9901. Springer, Cham. https://doi.org/10.1007/978-3-319-46723-8_48
Download citation
DOI: https://doi.org/10.1007/978-3-319-46723-8_48
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-319-46722-1
Online ISBN: 978-3-319-46723-8
eBook Packages: Computer ScienceComputer Science (R0)