
Abstract
After chronic low back pain, Temporomandibular Joint (TMJ) disorders are the second most common musculoskeletal condition affecting 5 to 12% of the population, with an annual health cost estimated at $4 billion. Chronic disability in TMJ osteoarthritis (OA) increases with aging, and the main goal is to diagnosis before morphological degeneration occurs. Here, we address this challenge using advanced data science to capture, process and analyze 52 clinical, biological and high-resolution CBCT (radiomics) markers from TMJ OA patients and controls. We tested the diagnostic performance of four machine learning models: Logistic Regression, Random Forest, LightGBM, XGBoost. Headaches, Range of mouth opening without pain, Energy, Haralick Correlation, Entropy and interactions of TGF-β1 in Saliva and Headaches, VE-cadherin in Serum and Angiogenin in Saliva, VE-cadherin in Saliva and Headaches, PA1 in Saliva and Headaches, PA1 in Saliva and Range of mouth opening without pain; Gender and Muscle Soreness; Short Run Low Grey Level Emphasis and Headaches, Inverse Difference Moment and Trabecular Separation accurately diagnose early stages of this clinical condition. Our results show the XGBoost + LightGBM model with these features and interactions achieves the accuracy of 0.823, AUC 0.870, and F1-score 0.823 to diagnose the TMJ OA status. Thus, we expect to boost future studies into osteoarthritis patient-specific therapeutic interventions, and thereby improve the health of articular joints.
Similar content being viewed by others

Introduction
Osteoarthritis (OA) affects millions of people worldwide, causing them many years with pain and disability1. Trends in the global burden of the disease from 1990 to 2016 show that OA is the second most rapidly rising condition associated with disability, with a 46 percent increase in years lived with disability, just behind diabetes at 52 percent2. With the aging population and higher rates of obesity, this burden is expected to rise. The rapid increase in the prevalence of OA will lead to a growing impact and major challenges for health care and public health systems. OA can occur in different joints in the musculoskeletal system, such as the knee, hips, back, hand, and temporomandibular joint (TMJ), having a multifactorial etiology that includes: excessive mechanical stress, hormonal changes, genetics, aging and others3,4,5. The TMJ is a unique model to study early bone changes in OA, as the articular bone surface is covered only by a thin layer of fibrocartilage in the TMJ condyle. Osteoarthritis of the TMJ (TMJ OA) is a multi-system disease, involving numerous pathophysiological processes, and requiring comprehensive assessments to characterize progressive cartilage degradation, subchondral bone remodeling, and chronic pain4,6,7,8.
Studies using in vivo OA disease models now benefit from high-resolution cone-beam tomography imaging (HR-CBCT)9. HR-CBCT scans allow diagnosis of the bone environment with sub-millimeter resolution comparable to micro-CT, but with a much lower radiation dose10, and have been widely used by clinicians and researchers11,12,13,14. As treatments to reverse the chronic damage of TMJ OA are unavailable, early diagnosis may provide the best opportunity to prevent extensive and permanent joint damage. However, current diagnosis is based on pre-existent clinical/imaging signs and symptoms markers using standard protocols recommended for Diagnostic Criteria for Temporomandibular Disorders (DC/TMD), meaning to diagnose TMJ OA degradation of the joint must have already occurred15,16. The DC/TMD criteria are based on pre-existent condylar damage, such as subcortical cysts, surface erosions, osteophytes, or generalized sclerosis that are present mainly in the later stages of the disease. Towards an early diagnosis that is predictive of disease status, animal studies indicate that the bone microarchitecture6,8,17,18 is an important factor in the OA pathogenesis initiation, preceding articular cartilage changes17,19, and should be investigated in human studies. There is an estimated increase in OA prevalence over the next decades, which reflects in more data acquisition, demanding advances in computational machine learning and data management20,21,22. For this reason, there is a need for precise data mining algorithms, data capture, standardization, management and processing from multiple centers to provide personalized treatment and diagnosis15,20,22,23,24,25. For disease diagnosis, machine learning approaches have been applied in the medical field26,27,28,29. Most of the studies have pointed out algorithms and multi-source biomarkers to predict the disease status, such as XGBoost30, LightGBM31, deep learning algorithms32, random forest algorithms27, etc. The models have been tested with different features, including radiographic and magnetic resonance (MRI) data33,34, proteomics28, and clinical information27 for creating patient-specific prediction models23. However, most studies addressed the OA involvement in the knee. For the temporomandibular joint, we found two studies that were done by our group evaluating only the morphological changes in mandibular condyles35,36. In addition, most of the literature is focused on multi-center database, or late stages of OA (chronic stages) assessed using routine exams. Here, we addressed surrogate biomarkers such as the radiomics, which can be useful to explore the subchondral bone organization and maybe play a pivotal role in a true early diagnosis of the TMJ OA.
We propose novel standardized data representation/processing, statistical learning, and interactive visualization to fully explore biomarker interactions to disease and health. Our data-driven approaches integrate information patterns to provide new insights into the complex etiology of TMJ OA37. Data management includes standardized imaging38, clinical15 and biomolecular39 acquisition, and control of patient information from multiple data sources, with standardized demographic for matching OA patients and healthy controls. We have evaluated fifty-two variables to determine the most relevant integrative feature pools using machine-learning algorithms to detect TMJ OA status (Fig. 1). We hypothesize that by combining standardized patient features from multiple sources using statistical machine-learning approaches, we can accurately diagnose TMJ OA status.

The spectrum of Data Science to advance TMJ OA diagnosis includes Data capture and acquisition, Data processing with a web-based data management, Data Analytics involving in-depth statistical analysis, machine learning approaches, and Data communication to help the decision-making support in TMJ OA diagnosis.
Results
Web-based platform to store and compute data analytics of clinical, radiomics and biomolecular markers
Our Data Storage for Computation and Integration (DSCI)40 web-based system was used for data management with storage and integration of patient information from multiple sources. The DCSI communicates with 3D Slicer41 platform through the Data Base lnteractor42 plugin that allows the user to upload the clinical, imaging and biological markers. The data was exported in a.csv file and we show in Tables 1–3, the descriptive statistics for each variable and their respective nomenclature. As most of the variables did not show parametric distribution (after evaluation of the asymmetry, kurtosis and Shapiro-wilk test), the descriptive statistics display the median, mean, standard deviation and upper/lower limits for the 95% confidence interval. The following variables were measured only for the TMJ OA group since the control patients did not present facial and/or TMJ pain: years of pain onset (PainY), current facial pain (PainCur), last six months worst facial pain (PainWor) and last six months average facial pain (PainAve). The TMJ OA and control groups were age and sex matched. We can note that patients with OA present less range of mouth opening, for radiomics and biomolecular variables both present similar values and in Supplementary Fig. 1 we present the statistical differences between them. Finally, the MMP3 protein was not described for saliva, since the expression levels were not detected.
Radiomic features differentiate control subjects and TMJ OA patients
We used a non-invasive protocol validated by our group to detect the initial morphological changes in the mandibular condyle trabecular bone based on radiomics information10. We extracted 20 imaging features (GLCM, GLRLM and bone morphometry described in Table 2 12,38. These radiomic features were tested using the Mann-Whitney U test (Fig. 2B, Supplementary Fig. 1B and Supplementary Data 1) for group comparisons. From the 20 variables, 13 showed statistically significant differences between the disease and control groups. These findings suggest, and corroborate the literature, that the trabecular bone has an important role in the TMJ OA pathogenesis6,17,43.

Mann-Whitney U test comparison between the TMJ OA and control groups showing the variables included in our diagnosis prediction models; (A) Biomolecular features; (B) Radiomics features; (C) Clinical features.
Control and TMJ OA patients present similar expression levels of selected serum and saliva protein biomarkers
We selected proteins that have previously been detected in the TMJ synovial fluid of OA patients39. We collected saliva and serum using less invasive procedures and promising screening diagnostic tools44 to evaluate the diagnostic performance of each protein and their interactions with radiomics and clinical markers. To analyze each protein’s expression level, we used a customized human protein micro-array kit (RayBiotech, Norcross, GA) with duplicate samples for each patient, controlling the standard curve and limiting expression as can be seen in Supplementary Fig. 2. In both the saliva and serum samples, the levels of proteins did not differ, and large data distribution variability was observed, as described in Table 3. We show in Fig. 2A and Supplementary Data 2, the Mann-Whitney U-test results for comparison between the TMJ OA and control groups. Even though our results showed no differences between our groups, the next sections detail the contribution and diagnostic performance of those proteins to diagnose TMJ OA status
Clinical features differentiate control subjects and TMJ OA patients
We present the Mann-Whitney U test in Supplementary Fig. 1c and Supplementary Data 3 for comparison of both groups for the following clinical variables: RangeAssMax, MusSor, RangeWOpain, Headaches and RangeUnaMax, defined in Table 1. We chose these features because they were measured in both groups and are part of the “Diagnostic Criteria for Temporomandibular Disorders (DC/TMD) for Clinical and Research Applications: Recommendations of the International RDC/TMD Consortium Network and Orofacial Pain Special Interest Group”15. Our results show that only RangeAssMax and RangeUnaMax were not statistically significantly different between the TMJ OA and control groups. The clinical features that presented statistically significant differences were correlated with pain or limited by pain. For example, for the maximum opening without pain (RangeWOpain), patients were instructed to open their mouths until they start to feel pain within their TMJs. This approach reduces the amount of opening for the TMJ OA patients that often present pain during opening; however, when the patients were asked to open the mouth as much as they could even with pain (i.e., RangeUnaMAx) the values were not statistically significant between the groups. In Fig. 2C, we display only the variables that were included in our diagnostic models, described in the following sections.
Diagnostic performance to predict TMJ OA status
We had 55 features shown in Tables 1–3 plus gender; however, 4 clinical features are expressed only in OA patients, and for this reason, were not included in the next analysis, resulting in a total of 52. In Fig. 3A, we show the values for the Area Under the curve (AUC), p-value, and q-value for 52 features. Figure 3B shows the AUC (upper), p-value (medium) and q-value (lower) for each category of variables (biological, clinical and radiomics). Most of the features with significant AUC values are clinical or radiomics; no biomolecular feature is detected with AUC > 0.65; nevertheless, it is shown that the interaction of biomolecular features can attain an AUC of 0.74 (Fig. 3C) and have a large contribution in prediction of TMJ OA status(Figs. 3B and 4).

(A,C) General association analysis of risk factors. The outer circle shows the AUC, middle circle shows the p-values, and the inner circle shows the q-values for each single feature. (A,C) for 52 features, and 39 interactions, respectively. (B,D) for 52 features and 1326 interactions, respectively. (B,D) The upper graphic shows the AUC, the middle graph shows the p-values, and the lower category shows the q-values for each category of features.

Top features with mean contribution (according to feature importance) greater than 80% for 10 times 5-fold CV. (A) Top 13 features in the XGBoost prediction model for 10 times 5-fold CV; (B) Top 7 features the LightGBM prediction model for 10 times 5-fold CV.
Contributions assessment of top features and interactions
Top features were filtered with {AUC > 0.7} calculated from the training subjects and then fed into an XGBoost30/LightGBM31 model to make diagnostic predictions. More details can be found in the Method section. We demonstrate (Fig. 4) the contributions of the top (>80% contribution in sum) features selected from the 52 features with mutual interactions, according to feature importance of XGBoost (Fig. 4A) and LightGBM (Fig. 4B) prediction models, using10 times 5-fold cross-validation,. We find that 13 features using the XGBoost model have a mean contribution larger than 80%, while for LightGBM a subset including 7 features contributes >80% information.
Diagnosis of TMJ OA status based on the top features and interactions
After the selection of the best features and interactions (Fig. 4), Fig. 5A displays the boxplots for comparison between OA and control groups. Figure 5B is showing the ROC curves of diagnostic sensitivity and specificity for individual features with top mean importance and the mean prediction of XGBoost, LightGBM and their ensemble method IN the 10-times 5-fold CV. The accuracy, precision, recall, AUC and F1-score of five described methods (\({{\mathscr{F}}}_{1},\,{{\mathscr{P}}}_{1}\)), (\({{\mathscr{F}}}_{2},\,{{\mathscr{P}}}_{1}\)), (\({{\mathscr{F}}}_{2},\,{{\mathscr{P}}}_{2}\)), (\({{\mathscr{F}}}_{2},\,{{\mathscr{P}}}_{3}\)), (\({{\mathscr{F}}}_{2},\,{{\mathscr{P}}}_{2}\)), (\({{\mathscr{F}}}_{2},\,{{\mathscr{P}}}_{2}+{{\mathscr{P}}}_{3}\)) and (\({{\mathscr{F}}}_{2},\,{{\mathscr{P}}}_{4}\)) (see method section) are shown in Table 4 using 10 times’ 5-fold cross-validation. Even though the main effect of biomolecular features is low, their interaction effects with clinical and radiomics features are important in diagnosis. For the 10 times’ 5-fold CV, the XGBoost + LightGBM with the interaction features achieves the best average accuracy of 0.823, AUC 0.870, and F1-score 0.823.

Top features to diagnose disease status. (A) Boxplots of normalized features; (B) ROC curves of diagnostic sensitivity and specificity for individual features with top mean importance and the mean prediction of XGBoost, LightGBM and their ensemble method IN the 10-times 5-fold CV.
Cross-validation to control for overfitting
In order to select risk factors from the high-dimensional 52 features plus 1326 interactions, the control of overfitting is necessary. To take advantage of a larger training sample size to fulfill this aim, we use the 10 times’ 5-fold cross-validation and give evaluation and comparison using the average performance of different approaches on validation subjects. Each time in the 10 times’ 5-fold CV, we select hyperparameters, i.e., the iteration steps, by further splitting the training subjects for 10-fold (or 5-fold) cross-validation.
Discussion
We report here, the diagnostic performance of machine learning approaches to predict TMJ osteoarthritis status. Through data acquisition, management and processing, we achieve one of the main challenges of healthcare delivery, which is to integrate the patient data information from multiple sources for accurate diagnosis and meaningful indicators of individual health45. To obtain patient-specific, precise diagnostic information, Data Science has become indispensable in medicine, with the integration of data capture, management/processing and in-depth analysis with rigorous and standardized protocols46,47.
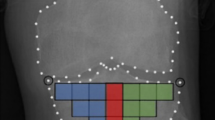
In the carefully controlled data acquisition methods of our study, all subjects had the same imaging acquisition protocol, all clinical assessments were performed by the same pain specialist, and a single investigator collected the clinical, biological and imaging data. This study database was composed initially of 107 subjects, and 15 subjects were excluded due to incomplete or inadequate quality of data. As part of the data management and processing, we extracted radiomics information from each subject’s HR-CBCT scan (Fig. 6) to obtain information that is hidden to the clinicians’ naked eyes48. Our result in Supplementary Fig. 1 shows that most radiomics features were able to differentiate between control and TMJ OA patients. Advanced statistical learning approaches, shown in Fig. 4, demonstrate among the radiomics features, that Entropy, Energy, HarCor, are included in our most accurate prediction models and corroborate our previous findings that found correlations between these features and the bone status38, where a decreased energy was associated with bone sclerosis/loss, and the increased values for HarCor and Entropy was correlated to bone sclerosis/loss. For the knee OA diagnosis, Brahim et al.26, (2019) using imaging features, evaluated the performance of machine learning algorithms to detect the disease, with x-rays radiographic from the public dataset Osteoarthritis Initiative (OAI). Their results showed an OA detection with 82.98% of accuracy using Random Forest and Naive Bayes classifiers. Even though the results were good, a standardization of the images was necessary to classify the images from multi-centers correctly. Here, we addressed this challenge, using a rigorous protocol for the imaging markers; however, our sample size (n = 46 per group) in comparison with Brahim et al.26 (n = 516 per group) was not enough to get a good accuracy only using the radiomics, where we found an AUC of 0.70 approximately (Energy, Entropy, Haralick Correlation, Inverse Difference Moment and Trabecular Separation). For this reason, we also included clinical features and biomolecular information that improved our diagnostic model performance. Also, we have found in the literature only two papers showing the application of machine learning approaches in the temporomandibular joint osteoarthritis diagnosis, and both were focused on developing a model only for bone surface classification35,36.

Image volume of interested selection to extract radiomics and bone morphometry features.
All clinical data were obtained using the DC/TMD15 criteria. We have chosen features measured in both groups, as described in Fig. 3, where headaches had the highest AUC among all the features. This marker is highly correlated to temporomandibular disorders in the literature49, and now our study shows its improved diagnostic performance to predict OA status in conjunction with other features and machine learning approaches. Interestingly, the interaction of headaches with TGF-β1_Sal together was one of the top features with >80% mean contribution to information gain in our statistical learning models. A possible clinical explanation is that patients with headaches had increased levels of this protein, as previous studies have indicated the expression and correlation of this cytokine with mandibular bone degradation in TMJ OA patients50,51,52,53. Other clinical markers included in our disease model were: RangeWOpain and its interaction with PAI-1_Sal. As TMJ OA patients present with pain in their TMJs, the decreased amount of mouth opening without pain was an important disease sign with an AUC of 0.70; and its interaction with PAI-1_Sal was an exciting finding, as this feature was increased in the OA patients (Fig. 4). PAI-1 is a serine protease inhibitor of tissue plasminogen activator and prevents the formation of plasmin; in OA, PAI-1 has a role in the cascade of enzymatic activities, compromising repair and increasing the cartilage degradation19,54. A recent study by our group showed that PAI-1 is correlated with areas of flattening in the lateral surface of mandibular condyles with OA39, corroborating the results of this study. For the demographic’s aspect, Gender and its interaction with MusSor was another significant feature included in our statistical prediction models. However, as TMJ OA prevalence is higher in women55, a limitation of this study is the unequal number of male and female subjects; out of the 46 subjects in each group (sample size n = 92), 39 were females and only 7 males. The role of MusSor in this interaction may be due to differences in pain sensitivity in women and men56, and to the central sensitization caused by painful osteoarthritis as patients with temporomandibular disorders also presented higher prevalence of muscle-related symptoms57. In our study, the variables and/or interactions of: PAI-1_Sal*Headaches (AUC: 0.697), RangeWOpain (AUC: 0.7), Headaches (AUC: 0.778), TGF-β1_Sal*Headaches (AUC: 0.707), Gender*MusSor (AUC: 0.716), VE-cad_Sal*Headaches (AUC: 0.698), Headaches*ShortRLowGLE (AUC: 0.692)), PAI-1_Sal*RangeWOpain (AUC: 0.701) were the clinical features presenting >80% mean contribution to information gain, included in LightGBM and/or XGBoost prediction models. A study from 201358 that also investigated clinical markers (age, sex, weight, height), and genes (FAS844, FAS670, FASL377, FASL124) with support vector machines and probabilistic neural networks found a high classification performance, showing an AUC of approximately 0.95. This study indicates that our findings may be improved with the addition of genetics information. However, besides the challenges involving genetic studies, here, we used relatively simple approaches to assess our features, that could be applied to the clinical practice.
For the biomolecular markers, no differences between OA and control subjects (Supplementary Fig. 2A) were found; however, our prediction models show that the interaction between VE-cad_Ser*ANG_Sal (AUC: 0.74), PAI-1_Sal*Headaches, TGF-β1_Sal*Headaches (AUC: 0.707), VE-cad_Sal*Headaches (AUC: 0.698), PAI-1_Sal*RangeWOpain (AUC: 0.701), TGF-β1_Sal*Headaches and PAI-1_Sal*RangeWOpain (AUC: 0.701) are top features with mean>80% contribution to the information gain in the XGBoost and LightGBM predictive models. As markers of inflammation, VE-cad, ANG, TGF-β1 and PAI-1 have been previously shown39 to be expressed in the TMJ synovial fluid and plasma and to be correlated with the condylar morphology in OA patients. It should be highlighted that in the present study, those markers were obtained from saliva and blood samples utilizing less invasive procedures for the patient, and circulating levels of pro-inflammatory proteins have been shown to contribute to the pathophysiology of disorders of the TMJ59. In addition, saliva has been described as a promising, accurate and non-invasive tool for a reliable diagnosis44. A study from Kellesarian et al.60, showed the cytokines profile in the synovial fluid of patients with TMJ disorders, and the most proteins that we used in our study were listed in their systematic review. For the knees OA, Hear et al.28, (2014) also evaluated the performance of machine learning algorithms using artificial neural network (TreeBagger decision tree) and cytokines from serum as features to classify patients with TMJ OA, rheumatoid arthritis and normal. Interestingly, the authors found only 12 statistically significant differences in the cytokines from the 38 studied, and the patients were classified based on late symptoms. The CNN showed the high performance to classify the patients (sensitivity and specify higher than 90%), and the author suggests that a combination of the cytokines is more critical for the classification than the individual levels, going towards to the findings of our present study.
In a diagnostic perspective, Ahmed et al.61 aimed to assess the early stages of knee OA. They used random forest, stepwise generalized linear model, generalized linear models with elastic net as classifiers and proteins from plasma, synovial fluid and serum as features, using leave one out cross-validation and k-fold cross-validation to test the model’s performance. The subjects were classified as early OA, control, early arthritis rheumatoid, and non-rheumatoid arthritis (other inflammatory arthritis). As results, the highest F1 score was for eOA diagnosis (0.78) and the lowest for non-RA (0.36) with GLMNET algorithm. In our study, we had a similar sample size and goal (detection of OA in an early stage), and we found a slightly better F1 score, close to 0.83. A recent study, in 201727, evaluated machine learning approaches for the identification of new biomarkers for knee osteoarthritis diagnosis. The baseline number of variables for each participant consisted of 186 features, including questionnaires (demographics, anamneses, pain, nutrition, etc.), radiography, magnetic resonance scores, physical/clinical examinations, biomarkers from serum, and urine, etc. The algorithm used was RGIFE (random forest algorithm), and for testing the model, they selected 10-fold cross-validation. The authors found five good prediction models, including different subsets of features in each. The overall discrimination of knee OA among the patients was considered good with good (AUC between 0.80 and 0.90). Each prediction model presented multi-source biomarkers such as clinical information, imaging-based information, pain, food questionnaires, and molecular markers. These results suggest that the disease has a complexity etiology, corroborating with our findings and confirming that there is a need to investigate the association of clinical, imaging, and proteins to better categorized this complex disease.
Nowadays, the complex, high-dimensional, and biomedical data from multiple sources benefit from data science, computational advances, and machine learning approaches to improve knowledge in terms of diagnosis, disease classification, clustering data, and disease progression prediction32,62,63,64. For osteoarthritis, studies using mathematical algorithms for diagnosis and personalized treatment decisions are increasing65. We have previously shown the diagnostic performance to predict the disease status based on the condylar surface morphology and deep learning approaches35,40, and now we show an integrative approach based on clinical, imaging radiomics and biomolecular patient-specific data. A limitation of this study is that the cross-sectional study design does not allow assessment of the disease progression and how different disease stages affect the proposed biomarkers. Other studies that assessed early stages of the knee OA using machine learning approaches33, used subjective radiologic interpretation of 2D x-rays, rather than the high-resolution 3D images included in the present study. Here, with the use of the radiomics, clinical, and protein information, our predictive model with XGBoost + LightGBM and 1378 features/interactions showed an accuracy of 0.823, AUC 0.870, and F1-score 0.823 to determine disease status. Future studies using the proposed machine learning models and longitudinal data will provide better information on the feature’s behavior and disease progression.
In conclusion, our in-depth statistical learning analysis was based on the integration and interactions of 52 features. We screened the diagnostic performance of each feature (Figs. 3–5) and built our machine learning models based on the most relevant features. Our final prediction model had an accuracy of 0.823 (SD: 0.029) to predict TMJ OA status using LightGBM + XGBoost with 1378 features interactions. Importantly, we show a comprehensive integration of new tools, data acquisition, management, and approaches to improve articular joint health and predict patient-specific TMJ OA status.
Methods
We followed the “Strengthening the Reporting of Observational studies in Epidemiology” (STROBE) guidelines for observational studies66. All experiments were performed in accordance with the guidelines and regulations approved by the Institutional Review Board approval (HUM00105204 and HUM00113199) from the University of Michigan and the informed consent was obtained from all participants.
Study design, setting and participants
After the Institutional Review Board approval (HUM00105204 and HUM00113199) from the University of Michigan, we enrolled patients and subjects from January 2016 to December 2018 that composed our TMJ OA and Control groups, respectively. This cross-sectional study sample was composed of 92 patients, 46 TMJ OA and 46 age and sex-matched control subjects who were selected based on rigorous inclusion criteria. The general health conditions of the participants included: age between 21–70 years old, no history of cancer, no history of jaw joint trauma, no previous surgery in the TMJ or recent jaw joint injections, absence of systemic diseases; no current pregnancy and no congenital bone or cartilage disease. All patients were examined by a single temporomandibular disorders specialist at the Hospital of the University of Michigan (Medicine Oral Surgery Clinic) through the Diagnostic Criteria for Temporomandibular Disorders (DC/TMD)15 for TMJ osteoarthritis diagnosis. The patients were diagnosed as early stages of TMJ osteoarthritis when they presented: pain in at least one TMJ for less than 10 years, TMJ noise during movement or function in the last 30 days and crepitus detected during mandibular excursive movements. The Control group subjects were recruited by advertisement and evaluated for the absence of TMJ OA clinical and radiographic signs and symptoms. The diagnosis for the TMJ OA group and side of choice (left or right) was confirmed utilizing the radiographic criteria16, including initial stages of subchondral cyst, erosion, generalized sclerosis and/or osteophytes. For the matching control condyle, the side of choice was the one without any clinical or radiographic findings. The exclusion criteria for the TMJ OA group were patients with middle to chronic TMJ OA diagnosis, evaluated when they present more than 10 years of TMJ pain diagnosis and/or severe stages of bone destruction, subchondral cyst, erosion and generalized sclerosis evaluated using the hr-CBCT by a radiologist.
Variables
Our study was composed by 3 main sub-groups of variables, which were: biomolecular features (composed by proteins of serum and saliva), imaging features (composed by trabecular bone radiomics and morphometry) and clinical features.
Biomolecular data
We evaluated 14 proteins in serum and saliva associated with arthritis initiation and progression, such as nociception, inflammation, angiogenesis and bone resorption, which were: 6ckine, Angiogenin, BDNF, CXCL16, ENA-78, MMP-3, MMP-7, OPG, PAI-1, TGFb1, TIMP-1, TRANCE, VE-Cadherin and VEGF. However, the expression of 6ckine was not expressed in the serum and saliva samples in this study, and MMP-3 was not expressed in saliva. The raw data can be seen in the Supplementary Fig. 2. The reason to select those proteins, besides their participation in the TMJ OA inflammation process60, was due to our previous studies that detected these markers in the TMJ synovial fluid and saliva of OA patients, showing correlations with bone surface changes35,39.
Blood and saliva acquisition protocol
The participants had 5 ml of venous blood collected by a trained nurse at the University of Michigan. The blood was centrifuged for 20 minutes at 1000 RPM to separate only the serum that was then aliquoted in 2 ml Eppendorf tubes and stored at −80C. For the saliva collection, the participants received a 14 ml sterile test tube with a funnel inserted; they were instructed to tilt their head forward and drip the saliva off into the tube until 2 ml was collected. They were informed to not spit, talk, or swallow during this process67.
Custom micro-array
Custom human quantibody protein microarrays obtained from RayBiotech, Inc. Norcross, GA, was used to quantitatively assess the saliva and serum samples for the 14 specific biomarkers. Each participant had duplicates run for the saliva and serum samples (detailed description provided by Jiang et al.68 and Huang et al.69). Supplementary Figures 2, 3 shows the raw values obtained for each participant and the standard curves for each protein.
Clinical signs and symptoms acquisition protocol
The same investigator collected and measured the clinical signs and symptoms of the participants based on the DC/TMD15 criteria. The variables measured and selected for further statistical analysis were: Age pain began in years - TMJ OA Group only, Current Facial Pain -TMJ OA Group only, Worst Facial Pain in last 6 months -TMJ OA Group only, Average Pain -TMJ OA Group only, Last 6 Months Distressed by Headaches, Last 6 Months Distressed by Muscle Soreness, Vertical Range Unassisted Without Pain (mm), Vertical Range Unassisted Maximum (mm), Vertical Range Assisted Maximum (mm).
Imaging data acquisition
We acquired cone-beam computed tomography scans of each subject using the 3D Accuitomo (J. Morita MFG. CORP Tokyo, Japan) machine at the University of Michigan, School of Dentistry. The protocol for the temporomandibular joint high-resolution CBCT was field of view 40 × 40 mm; 90 kVp, 5 mAs, scanning time of 30.8 s and a voxel size of 0.08 mm3. The images were exported in DICOM (.dcm) using the manufacture software: i-Dixel (J. Morita MFG. CORP Tokyo, Japan) and optimization manufacture filter: G_103 + H_009. Finally, the images were coded and de-identified to avoid investigator bias in the statistical analysis.
Imaging trabecular texture-based features
We previously described the optimal parameters to extract radiomics features from the HR-CBCT scans in our study conditions and we followed these parameters to extract the information from our imaging data, using the BoneTexture module38. The region analyzed was the internal condylar lateral region (Fig. 6) due to our pilot results that showed this region to be the most significantly different between Control and TMJ OA patients. The textural information evaluated were: Energy, Entropy, Inverse Difference Moment, Inertia, Haralick Correlation, Short Run Emphasis, Long Run Emphasis, Grey Level Non Uniformity, Run Length Non Uniformity, Low Grey Level Run Emphasis, High Grey Level Run Emphasis, Short Run Low Grey Level Emphasis, Short Run High Grey Level Emphasis, Long Run Low Grey Level Emphasis, Long Run High Grey Level Emphasis, Bone Volume, Trabecular Thickness, Trabecular Separation, Trabecular Number and Bone Surface to Bone Volume Ratio.
Exploratory tests
We first did a traditional statistical analysis to explore our data and to test the hypothesis that there is no difference between our groups. Our data does not show normality distribution and for this reason, we chose non-parametrical tests for our analysis. The descriptive analysis, Mann-Whitney U test was done using the software GraphPad Prisma V 8.11 (GraphPad Software, Inc., San Diego, CA). For the descriptive analysis, we showed the median in addition to the mean, the 95% confidence intervals and the standard deviation. The Mann-Whitney U test was used to test our hypothesis and we used a two-tailed test with α of 5%.
Machine learning approaches
We diagnose the OA/control disease status based on the 52 features including five clinical variables, 20 radiomics features, 25 biomolecular features (13 from serum and 12 from saliva) and two demographic variables (age and gender). First, we normalized all features to have zero mean and one standard deviation. Next, we calculated the AUROC (Area under the Receiver Operating Characteristic curve), p-value and q-value70 from a two-sample Mann-Whitney U test to evaluate the significance of each feature (Fig. 3). Afterward, we compared four different prediction methods, each of which follows the four steps: (I) Cross-validation to avoid overfitting (II) feature selection (III) risk prediction (IV) method evaluation. We used one-sided paired DeLong test71,72 to validate the significance of AUC comparison between different approaches.
Cross-validation (CV)
We applied the 10 times’ 5-fold CV by taking 4 folds as training and the remaining one-fold as validation with 10 times’ repetition. At each time, we normalized the original 52 features denoted as F1 based on the training subjects and then took the product between each pair of them to generate additional 1326 interactions and denoted the set of 1378 features as \({{\mathscr{F}}}_{2}\). We performed the following two-step procedures by using only the training dataset and feature pools \({{\mathscr{F}}}_{1}\) and \({{\mathscr{F}}}_{2}\), respectively, where \({{\mathscr{F}}}_{1}\) represents the set of original 52 features, and we took the product between each pair of \({{\mathscr{F}}}_{1}\) to generate an additional 1326 interactions and denoted the set of 1378 features as \({{\mathscr{F}}}_{2}\). Afterwards, we applied the 10 times’ 5-fold CV by taking 4 folds as training and the remaining one-fold as validation with 10 times’ repetition. This will further evaluate the sensitivity of the model.
Feature selection
We calculate the AUC for each single feature in \({{\mathscr{F}}}_{2}\) and select top features according to {f ∈ F1|AUC of f > 0.7} and {f ∈ F2|AUC of f > 0.7} for feature pools met F1 and F2, respectively.
Evaluation and risk prediction
We trained the logistic regression model (method P1), Extreme Gradient Boosting (XGBoost; method \({{\mathscr{P}}}_{2}\))30, Light Gradient Boosting Machine (LightGBM; method \({{\mathscr{P}}}_{3}\))31, and Random Forest (method \({{\mathscr{P}}}_{4}\))73 model by using the extracted features from the last step for risk prediction of the validation subject. For both XGBoost and LightGBM models, we fix the depth D = 1, and tune the iteration steps by further splitting the training subjects into training and validation subjects for 10-fold cross validation, where AUC is chosen as the evaluation criterion. We evaluate the prediction performance of six pairs of feature set and methods (\({{\mathscr{F}}}_{1},\,{{\mathscr{P}}}_{1}\)), (\({{\mathscr{F}}}_{2},\,{{\mathscr{P}}}_{1}\)), (\({{\mathscr{F}}}_{2},\,{{\mathscr{P}}}_{2}\)), (\({{\mathscr{F}}}_{2},\,{{\mathscr{P}}}_{3}\)), (\({{\mathscr{F}}}_{2},\,{{\mathscr{P}}}_{4}\)) and (\({{\mathscr{F}}}_{2},\,{{\mathscr{P}}}_{2}+{{\mathscr{P}}}_{3}\)) by using the accuracy, precision, recall, AUROC and \({{\mathscr{F}}}_{1}\)-score74 on the 10 times 5-fold validation subjects. We also compare the results with other different hyperparameters. For example, we show in Table 4 the results for min_child_weight W∈{1,2}, colsample_bytree C∈{0.5,0.7}, subsample S∈ {0.5,0.7} and the learning rate η∈{0.001,0.01}. Our results showed that the XGBoost and LightGBM model by averaging the prediction probability (\({{\mathscr{F}}}_{2},\,{{\mathscr{P}}}_{2}+{{\mathscr{P}}}_{3}\)) has the best performance on the validation subjects in the 10 times 5-fold CV; here the combination of XGBoost and LightGBM is recommended for its robustness in 10 times’ 5-fold CV.
Data availability
The data analyzed are available from the corresponding author on a reasonable request.
Code availability
Source code for the Computation and Integration web system (DSCI) is available at https://github.com/DCBIA-OrthoLab/shiny-tooth, for the DataBase interactor 3D-slicer Plugin: https://github.com/DCBIA-OrthoLab/DatabaseInteractorExtension and for the imaging markers extraction the code is available at https://github.com/Kitware/BoneTextureExtension.
References
Vos, T. et al. Global, regional, and national incidence, prevalence, and years lived with disability for 328 diseases and injuries for 195 countries, 1990–2016: A systematic analysis for the Global Burden of Disease Study 2016. Lancet 390, 1211–1259 (2017).
March, L. & Cross, M. Epidemiology and risk factors for osteoarthritis. Available at, https://www.uptodate.com/contents/epidemiology-and-risk-factors-for-osteoarthritis.
Herrero-Beaumont, G., Roman-Blas, J. A., Castañeda, S. & Jimenez, S. A. Primary Osteoarthritis No Longer Primary: Three Subsets with Distinct Etiological, Clinical, and Therapeutic Characteristics. Semin. Arthritis Rheum. 39, 71–80 (2009).
Wang, X. D., Zhang, J. N., Gan, Y. H. & Zhou, Y. H. Current Understanding of Pathogenesis and Treatment of TMJ Osteoarthritis. J. Dent. Res. 94, 666–673 (2015).
National Institute of Dental and Craniofacial Research. Facial Pain. Available at, https://www.nidcr.nih.gov/research/data-statistics/facial-pain.
Embree, M. et al. Role of Subchondral Bone during Early-stage Experimental TMJ Osteoarthritis. J. Dent. Res. 90, 1331–1338 (2011).
Wang, X. D., Zhang, J. N., Gan, Y. H. & Zhou, Y. H. Current understanding of pathogenesis and treatment of TMJ osteoarthritis. J. Dent. Res. 94, 666–73 (2015).
Jiao, K. et al. Subchondral bone loss following orthodontically induced cartilage degradation in the mandibular condyles of rats. Bone 48, 362–371 (2011).
Nieminen, M. T., Casula, V., Nevalainen, M. T. & Saarakkala, S. Osteoarthritis year in review 2018: imaging. Osteoarthr. Cartil. 27, 401–411 (2019).
Ebrahim, F. H. et al. Accuracy of biomarkers obtained from cone beam computed tomography in assessing the internal trabecular structure of the mandibular condyle. Oral Surg. Oral Med. Oral Pathol. Oral Radiol. 124, 588–599 (2017).
Pauwels, R., Araki, K., Siewerdsen, J. H. & Thongvigitmanee, S. S. Technical aspects of dental CBCT: State of the art. Dentomaxillofacial Radiol. 44, 1–20 (2015).
Paniagua, B. et al. Validation of CBCT for the computation of textural biomarkers. Proc. SPIE–the Int. Soc. Opt. Eng. 9417, 1–15 (2015).
Panmekiate, S., Ngonphloy, N., Charoenkarn, T., Faruangsaeng, T. & Pauwels, R. Comparison of mandibular bone microarchitecture between micro-CT and CBCT images. Dentomaxillofacial Radiol. 44 (2015).
Buch, K. et al. Quantitative assessment of variation in CT parameters on texture features: Pilot study using a nonanatomic phantom. Am. J. Neuroradiol. 38, 981–985 (2017).
Schiffman, E. et al. Diagnostic Criteria for Temporomandibular Disorders (DC/TMD) for Clinical and Research Applications: Recommendations of the International RDC/TMD Consortium Network* and Orofacial Pain Special Interest Group†. Journal of Oral & Facial Pain and Headache 28, 6–27 (2014).
Ahmad, M. et al. Research diagnostic criteria for temporomandibular disorders (RDC/TMD): development of image analysis criteria and examiner reliability for image analysis. Oral Surgery, Oral Med. Oral Pathol. Oral Radiol. Endodontology 107, 844–860 (2009).
Li, G. et al. Subchondral bone in osteoarthritis: insight into risk factors and microstructural changes. Arthritis Res. Ther. 15, 223 (2013).
Chen, J. et al. Altered functional loading causes differential effects in the subchondral bone and condylar cartilage in the temporomandibular joint from young mice. Osteoarthr. Cartil. 17, 354–61 (2009).
Brandt, K. D. & Radin, E. L. & Dieppe, P. a. Not a Cartilage Disease. Ann. Rheum. Dis. 65, 1261–1265 (2006).
Hunter, D. J. & Bierma-Zeinstra, S. Osteoarthritis. Lancet 393, 1745–1759 (2019).
Ghahramani, Z. Probabilistic machine learning and artificial intelligence. Nature 521, 452–459 (2015).
Raghupathi, W. & Raghupathi, V. Big data analytics in healthcare: promise and potential. Heal. Inf. Sci. Syst. 2, 3 (2014).
Jamshidi, A., Pelletier, J. P. & Martel-Pelletier, J. Machine-learning-based patient-specific prediction models for knee osteoarthritis. Nat. Rev. Rheumatol. 15, 49–60 (2019).
O’Connor, J. P. B. et al. Imaging biomarker roadmap for cancer studies. Nat. Rev. Clin. Oncol. 14, 169–186 (2017).
Johnson, V. L., Giuffre, B. M. & Hunter, D. J. Osteoarthritis: What does imaging tell us about its etiology? Semin. Musculoskelet. Radiol. 16, 410–418 (2012).
Brahim, A. et al. A decision support tool for early detection of knee OsteoArthritis using X-ray imaging and machine learning: Data from the OsteoArthritis Initiative. Comput. Med. Imaging Graph. 73, 11–18 (2019).
Lazzarini, N. et al. A machine learning approach for the identification of new biomarkers for knee osteoarthritis development in overweight and obese women. Osteoarthr. Cartil. 25, 2014–2021 (2017).
Heard, B. J. et al. A computational method to differentiate normal individuals, osteoarthritis and rheumatoid arthritis patients using serum biomarkers. J. R. Soc. Interface 11 (2014).
Donoghue, C. R. Analysis of MRI for Knee Osteoarthritis using Machine Learning. Dep. Comput. Imp. Coll. London 199 (2013).
Chen, T. & Guestrin, C. Xgboost: A scalable tree boosting system. In Proceedings of the 22nd acm sigkdd international conference on knowledge discovery and data mining 785–794 (ACM, 2016).
Ke, G. et al. Lightgbm: A highly efficient gradient boosting decision tree. In Advances in Neural Information Processing Systems 3146–3154 (2017).
Miotto, R., Wang, F., Wang, S., Jiang, X. & Dudley, J. T. Deep learning for healthcare: Review, opportunities and challenges. Brief. Bioinform. 19, 1236–1246 (2017).
Tiulpin, A., Thevenot, J., Rahtu, E., Lehenkari, P. & Saarakkala, S. Automatic Knee Osteoarthritis Diagnosis from Plain Radiographs: A Deep Learning-Based Approach. Sci. Rep. 8, 1727 (2018).
Chaudhari, A. S. et al. Utility of deep learning super-resolution in the context of osteoarthritis MRI biomarkers. J. Magn. Reson. Imaging 51, 768–779 (2020).
Shoukri, B. et al. Minimally Invasive Approach for Diagnosing TMJ Osteoarthritis. J. Dent. Res. 98, 1103–1111 (2019).
de Dumast, P. et al. SVA: Shape variation analyzer. Proc. SPIE–the Int. Soc. Opt. Eng. 10578, 89 (2018).
Nelson, A. E. et al. A machine learning approach to knee osteoarthritis phenotyping: data from the FNIH Biomarkers Consortium. Osteoarthr. Cartil. 27, 994–1001 (2019).
Bianchi, J. et al. Software comparison to analyze bone radiomics from high resolution CBCT scans of mandibular condyles. Dentomaxillofac. Radiol. 20190049, https://doi.org/10.1259/dmfr.20190049 (2019)
Cevidanes, L. H. S. et al. 3D osteoarthritic changes in TMJ condylar morphology correlates with specific systemic and local biomarkers of disease. Osteoarthr. Cartil. 22, 1657–67 (2014).
Michoud, L. et al. A web-based system for statistical shape analysis in temporomandibular joint osteoarthritis. Proc. SPIE–the Int. Soc. Opt. Eng. 10953 (2019).
Pieper, S., Halle, M. & Kikinis, R. 3D Slicer. In 2004 2nd IEEE international symposium on biomedical imaging: nano to macro (IEEE Cat No. 04EX821) 632–635 (IEEE, 2004).
Mirabel, C. DatabaseInteractor. Available at, https://www.slicer.org/wiki/Documentation/Nightly/Modules/DatabaseInteractor.
Goldring, M. B. & Goldring, S. R. Articular cartilage and subchondral bone in the pathogenesis of osteoarthritis. Ann. N. Y. Acad. Sci. 1192, 230–7 (2010).
Pfaffe, T., Cooper-White, J., Beyerlein, P., Kostner, K. & Punyadeera, C. Diagnostic potential of saliva: Current state and future applications. Clin. Chem. 57, 675–687 (2011).
Alyass, A., Turcotte, M. & Meyre, D. From big data analysis to personalized medicine for all: challenges and opportunities. 1–12, https://doi.org/10.1186/s12920-015-0108-y (2015).
Marx, V. Biology: The big challenges of big data. Nature 498, 255–60 (2013).
Sejdić, E. Medicine: Adapt current tools for handling big data. Nature 507, 306 (2014).
Gillies, R. J., Kinahan, P. E. & Hricak, H. Radiomics: Images Are More than Pictures, They Are Data. Radiology, https://doi.org/10.1148/radiol.2015151169 (2016).
Ciancaglini, R. & Radaelli, G. The relationship between headache and symptoms of temporomandibular disorder in the general population. 29 (2001).
Güzel, I., Taşdemir, N., Celik, Y. & Çelik, Y. Evaluation of serum transforming growth factor β1 and C-reactive protein levels in migraine patients. Neurol. Neurochir. Pol. 47, 357–362 (2013).
Bruno, P. P., Carpino, F., Carpino, G. & Zicari, A. An overview on immune system and migraine. Eur. Rev. Med. Pharmacol. Sci. 11, 245 (2007).
Jiao, K. et al. Overexpressed TGF-β in subchondral bone leads to mandibular condyle degradation. J. Dent. Res. 93, 140–147 (2014).
Ishizaki, K. et al. Increased Plasma Transforming Growth Factor-β1 in Migraine. Headache J. Head Face Pain 45, 1224–1228 (2005).
Ghosh, P. & Cheras, P. A. Vascular mechanisms in osteoarthritis. Best Pract. Res. Clin. Rheumatol. 15, 693–709 (2001).
Rando, C. & Waldron, T. TMJ osteoarthritis: A new approach to diagnosis. Am. J. Phys. Anthropol. 148, 45–53 (2012).
Sarlani, E., Garrett, P. H., Grace, E. G. & Greenspan, J. D. Temporal summation of pain characterizes women but not men with temporomandibular disorders. J. Orofac. Pain 21, 309–17 (2007).
Bajaj, P. P. et al. Osteoarthritis and its association with muscle hyperalgesia: an experimental controlled study. Pain 93, 107–114 (2001).
Aksehirli, Ö., Aydin, D., Ankarali, H. & Sezgin, M. Knee Osteoarthritis Diagnosis Using Support Vector Machine and Probabilistic Neural Network. Int. J. Comput. Sci. Issues 10, 283–291 (2013).
Slade, G. D. et al. Cytokine biomarkers and chronic pain: association of genes, transcription, and circulating proteins with temporomandibular disorders and widespread palpation tenderness. Pain 152, 2802–12 (2011).
Kellesarian, S. V. et al. Cytokine profile in the synovial fluid of patients with temporomandibular joint disorders: A systematic review. Cytokine 77, 98–106 (2016).
Ahmed, U. et al. Biomarkers of early stage osteoarthritis, rheumatoid arthritis and musculoskeletal health. Sci. Rep. 5, 1–7 (2015).
Swan, A. L., Mobasheri, A., Allaway, D. & Liddell, S. Application of Machine Learning to Proteomics Data: Classification and Biomarker Identification in Postgenomics Biology. 17 (2013).
Deng, L. et al. PDRLGB: Precise DNA-binding residue prediction using a light gradient boosting machine. BMC Bioinformatics 19 (2018).
Vanneste, S., Song, J. J. & De Ridder, D. Thalamocortical dysrhythmia detected by machine learning. Nat. Commun. 9 (2018).
Ashinsky, B. G. et al. Machine learning classification of OARSI-scored human articular cartilage using magnetic resonance imaging. Osteoarthr. Cartil. 23, 1704–12 (2015).
Vandenbroucke, J. P. et al. Strengthening the Reporting of Observational Studies in Epidemiology (STROBE). Epidemiology 18, 805–835 (2009).
Kaczor-Urbanowicz, K. E. et al. Salivary exRNA biomarkers to detect gingivitis and monitor disease regression. J. Clin. Periodontol. 45, 806–817 (2018).
Jiang, W. et al. Protein expression profiling by antibody array analysis with use of dried blood spot samples on filter paper. J. Immunol. Methods 403, 79–86 (2014).
Huang, R. et al. A biotin label-based antibody array for high-content profiling of protein expression. Cancer Genomics and Proteomics 7, 129–141 (2010).
Storey, J. D. The positive false discovery rate: a Bayesian interpretation and the q-value. Ann. Stat. 31, 2013–2035 (2003).
Robin, X. et al. pROC: an open-source package for R and S+ to analyze and compare ROC curves. BMC Bioinformatics 12, 77 (2011).
DeLong, E. R., DeLong, D. M. & Clarke-Pearson, D. L. Comparing the areas under two or more correlated receiver operating characteristic curves: a nonparametric approach. Biometrics 44, 837–845 (1988).
Breiman, L. Random forests. Mach. Learn. 45, 5–32 (2001).
Lipton, Z. C., Elkan, C. & Naryanaswamy, B. Optimal thresholding of classifiers to maximize F1 measure. In Joint European Conference on Machine Learning and Knowledge Discovery in Databases 225–239 (Springer, 2014).
Acknowledgements
This study was supported by NIH grants R01DE024450, R01MH116527, R21DE025306 and funded in part by the Coordination for the Improvement of Higher Education Personnel (CAPES) - Finance Code 001.
Author information
Authors and Affiliations
Contributions
All authors reviewed, wrote and approved the submitted version of the manuscript. J.B. - Conception and design, acquisition of data, patients and subject’s recruitment and analysis of data; J.R.G. – Design, analysis, and interpretation of data; A.C.O.R. - Conception and design, acquisition of data, analysis, and interpretation of data; B.P. - Developed the software and code to imaging data extraction. J.C.P. - Developed the software and code to imaging data extraction. M.S. - Developed the software and code to imaging data extraction as well as guidance for statistical and machine learning interpretation. J.S. – Study design and biomolecular data extraction/analysis. W.G. - Study design and biomolecular data extraction/analysis. E.B. - Performed radiological interpretation and well as developed the computed tomography acquisition. F.S. – Performed radiological interpretation and well as developed the computed tomography acquisition. M.Y. – Design, analysis, and interpretation of data; T.L. - Developed the mathematical theory and performed the statistical computations for machine learning. H.Z. - Developed the mathematical theory and performed the statistical computations for machine learning. L.A. - Conception and design and pain specialist that made the acquisition of patients. D.W- Analysis and interpretation of data critical and review of the English language, R.S. - Design and interpretation of data as well as machine learning interpretation. K.N. – Design, and interpretation of data as well as machine learning interpretation. L.H.S.C. - Conception and design, acquisition of data, analysis, and interpretation of data.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons license, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons license and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this license, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Bianchi, J., de Oliveira Ruellas, A.C., Gonçalves, J.R. et al. Osteoarthritis of the Temporomandibular Joint can be diagnosed earlier using biomarkers and machine learning. Sci Rep 10, 8012 (2020). https://doi.org/10.1038/s41598-020-64942-0
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-020-64942-0
This article is cited by
-
Machine learning-based medical imaging diagnosis in patients with temporomandibular disorders: a diagnostic test accuracy systematic review and meta-analysis
Clinical Oral Investigations (2024)
-
Clinical and radiomics feature-based outcome analysis in lumbar disc herniation surgery
BMC Musculoskeletal Disorders (2023)
-
An artificial intelligence model for the radiographic diagnosis of osteoarthritis of the temporomandibular joint
Scientific Reports (2023)
-
Neuroimaging and artificial intelligence for assessment of chronic painful temporomandibular disorders—a comprehensive review
International Journal of Oral Science (2023)
-
Application of a nomogram to radiomics labels in the treatment prediction scheme for lumbar disc herniation
BMC Medical Imaging (2022)
Comments
By submitting a comment you agree to abide by our Terms and Community Guidelines. If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.
