
Abstract
In this study, we investigated whether awareness of objects is necessary for object-based guidance of attention. We used the two-rectangle method (Egly, Driver, & Rafal, 1994) to probe object-based attention and adopted the continuous flash suppression technique (Tsuchiya & Koch, 2005) to control for the visibility of the two rectangles. Our results show that object-based attention, as indexed by the same-object advantage—faster response to a target within a cued object than within a noncued object—was obtained regardless of participants’ awareness of the objects. This study provides the first evidence of object-based attention under unconscious conditions by showing that the selection unit of attention can be at an object level even when these objects are invisible—a level higher than the previous evidence for a subliminally cued location. We suggest that object-based attentional guidance plays a fundamental role of binding features in both the conscious and unconscious mind.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
Attention serves as the first step of detailed processing at one location at the expense of other locations due to the limited capacity available—namely, location-based attention (e.g., Posner, 1980). According to the influential feature integration theory, various features belonging to the same location are processed in parallel and combined only when attention moves there (Treisman & Gelade, 1980). After feature integration, the combined percept is compared with the stored representation of the object (Treisman 1996), leading to a conscious percept of the object.
What remains unknown, therefore, is whether attention can further operate on the whole object (i.e., object-based attention; see, e.g., Vecera & Farah, 1994) even when the object is invisible—more specifically, whether attention can select an object even when we are not conscious of it, just as attention can select a location even without consciousness (Bahrami, Lavie, & Rees, 2007; Jiang, Costello, Fang, Huang, & He, 2006; Mulckhuyse, Talsma, & Theeuwes, 2007). Ecologically, the ability to make speedy correct fight-or-flight responses is important for survival. To an animal, the decision to fight or flee depends on whether it sees a prey or an enemy. To recognize objects immediately, spatial information is important but insufficient; processing of properties belonging to the same object is also critical. Because many objects are out of our consciousness in the over-complex visual world, we hypothesize that not only location-based attention, but also object-based attention can be influenced by unconscious information to advantage surviving.
In contrast to our hypothesis, however, Ariga, Yokosawa, and Ogawa (2007) argued that awareness of objects is necessary for object-based attention. They adopted the two-rectangle method (Egly, Driver, & Rafal, 1994) that contained two rectangles, with one end of one rectangle flashing a small circle as a cue to indicate the possible location of a target. The target was shown subsequently within one end of a rectangle. Object-based attention was indicated by the same-object advantage: Reaction times (RTs) were shorter when the target appeared at the uncued end of the cued than when it appeared at the uncued rectangle, with an equal cue-to-target distance between the two. Ariga et al. used objects that were defined by perceptual completion—that is, illusory objects—and found that the same-object advantage was not obtained in the condition when observers were unaware of the illusory objects.
We noticed that in Ariga et al.’s (2007) study, awareness was manipulated by changing the object preview time. Therefore, in their unconscious-object condition (Experiment 2), the objects and the target were presented simultaneously; that is, there was no object preview time. At least two studies from different groups imply that such a design may not be favorable for obtaining the same-object advantage. First, Davis and Holmes (2005) argued that the same-object advantage reflects strong within-object feature binding by mechanisms in the parvocellular to ventral-stream pathway that is responsible for object recognition. According to Davis and Holmes, the simultaneous presentation of the target and objects in Ariga et al. would weaken the contribution of this pathway because of the transient signals of the two; this would reduce or even eliminate the same-object advantage. Second, Shomstein and Behrmann (2008) showed that varying the object preview time changes the magnitude of the same-object advantage; the same-object advantage is observed only if there is ample object preview time to establish the object representation.
On the basis of these differing studies, we further hypothesize that it is preview time, but not awareness, that determines object-based attention: Given sufficient object preview time to successfully establish object representation, even invisible objects can lead to object-based attention. Despite a prevalent assumption that a long processing time unavoidably leads to the involvement of awareness and methodological difficulties in teasing apart the influences of processing time and awareness, it has been shown that the two can be dissociated in separate processing streams for implicit and explicit visual perception (Lo & Yeh, 2008).
To provide a long-enough object preview time, we used the newly developed paradigm called continuous flash suppression (CFS; Tsuchiya & Koch, 2005). In this paradigm, constantly changing high-contrast patterns are flashed to one eye that provide strong interocular suppression signals to a static stimulus presented to the other eye. Critically, the suppression of the static stimulus can last for quite some time (see Lin & He, 2009, for a review). Unlike other paradigms used for manipulating awareness (e.g., masking or crowding) wherein awareness is manipulated by changing visual stimulation (e.g., either masked or not), CFS has the merit of keeping visual stimulation invariant and surmounting the limitations of binocular rivalry (e.g., relatively short suppression duration and uncontrolled variation of one percept to another) in studying consciousness. By adopting the CFS technique in the present study, visual objects could be shown to observers with a relatively long preview time (1,900 ms).
Method
Participants
Twenty National Taiwan University undergraduate students participated in this study. All had normal or corrected-to-normal vision and were naïve as to the purpose of the experiment. They gave written informed consent to participate in this study, which was approved by the local ethics committee of the Psychology Department at National Taiwan University.
Apparatus, stimuli, and design
The stimuli were presented on a VGA monitor with the resolution of 640 × 480 pixels in a 256-color mode. A visual C++ computer program was run on an IBM-compatible computer to present the stimuli and collect the data. The participant sat in a dimly lit chamber with a viewing distance of 57 cm. Head position was maintained with a chin rest.
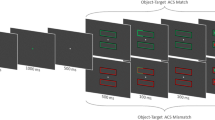
Two different images—both surrounded by a frame (10.7° × 10.7° of visual angle, with a thickness of 0.2°) that was composed of random dots—were projected onto each eye through a four-mirror stereoscope (see Fig. 1 for an illustrated depiction). Figure 2 illustrates the stimuli and sequence of events for a trial that contained objects (the object trial). The objects were always two horizontal rectangles in order to avoid the possible confounding that might occur because the two same-object locations would be in the same visual hemifield if they were vertical rectangles. Dominant-eye images comprised 5.5° × 5.5° Mondrian patches, constructed from random-size small patches (one side length from 0.01° to 1.07°) with a randomly chosen color (RGB values from 0 to 255) and changed at a 10-Hz flashing rate. Nondominant-eye images comprised two rectangles. Each rectangle (2° × 8°, with a stroke width of 0.2°) was centered 3° from fixation. The fixation was a red plus sign (1° × 1°). The cue and the target were identical (a 1° × 1° solid black patch), and all were centered 4.24° from fixation. The dynamic Mondrians (the masks) were presented to the dominant eye to provide stronger suppression to the horizontal rectangles that were presented to the nondominant eye. The fixation, cue, and target were presented to both eyes.

Stimuli rendered invisible with the continuous flash suppression (CFS) paradigm

Procedure of the object trial (for the no-object trials, no rectangles were shown). Each frame lasted for 100 ms. This is an example of the invalid-same object trial
In the unaware block, the contrast of the rectangles was raised gradually from 0% to 6% within 300 ms and was then kept constant at 6% until the end of the trial. In the aware block, the contrast of the rectangles was 100%. The spatial precue was presented at one end of a rectangle, with one of the three cue–target relationships:
-
1.
Valid: The target appeared at the cued location.
-
2.
Invalid same object (IS): The target appeared at the uncued location within the cued object.
-
3.
Invalid different object (ID): The target appeared at the near end of the uncued object.
The distance between the cue and the target was the same in the IS and ID conditions, making any RT difference between the IS and ID conditions not attributable to location. In each aware and unaware block, there were 12 object trials, including 4 valid, 4 IS, and 4 ID trials, which were mixed with 22 no-object trials (foils). Inserting foils helped participants fuse steadily under the dichoptic viewing situation, according to our pilot study. All trials were presented in a random order within each block.
The stimuli and procedure of the no-object trials were identical to those of the object trials, except that there were no rectangles. Despite the absence of rectangles in the no-object trials, we still used the same denotations (valid, IS, ID) based on the two imagery horizontal rectangles. The proportions of valid, IS, ID, and target-absent trials (catch trials) of the no-object trials were 70%, 10%, 10%, and 10%, respectively.
Structure of the experiment
Figure 3 depicts the structure of the experiment. First, a dominant eye measurement was conducted: Participants used the thumb and index finger of their right hand to make a circle and view an object on the wall binocularly through this circle, closing the left or right eye alternatively to determine which eye could still see the object through the circle when the other eye was closed. The eye that could still see the object was treated as the dominant eye. In the beginning of the CFS procedure, after the participant successfully fused the dichoptic images, the experimenter started the target detection task with the practice stage, which contained 20 no-object trials that were randomly selected from the training stage. After the practice stage and a short break, the training stage (34 no-object trials) and the critical stage (12 object trials mixed with 22 no-object trials) of the unaware block were conducted in sequence without a break. After the unaware block and another short break, the aware block was conducted. The aware block was identical to the unaware block, except that 100% contrast rectangles were used instead. The purpose of including the training stages, which were composed of no-object trials, was to train participants to use the informative spatial cue.

The structure of the experiment
After conducting the target detection task, participants were asked to perform the object detection task to assess their state of awareness of the rectangles. The object detection task contained 12 trials, including 4 trials randomly selected from the object trials of the unaware block, 4 trials randomly selected from the object trials of the aware block, and 4 no-object trials. All trials were presented in a random order. The stimuli and procedure on the object detection trials were identical to those on the target detection trials, except that participants were asked to detect the rectangles but not the target.
After collecting all the RT and accuracy data, the participant was asked an open question: “Did you see any figures in addition to the cue, target, fixation, and Mondrians during the first and the second experimental blocks?”
Procedure
Each trial began with a fixation display containing the fixation cross and two rectangles (or, on no-object trials, nothing) with a 1,600-ms duration. Following the fixation display, the cue display was presented for 100 ms and then replaced by a 200-ms fixation display, making the cue-to-target stimulus onset asynchrony 300 ms and the object preview time 1,900 ms. Then the target (or, on the catch trials, nothing) was presented and remained visible until the participants responded; if there was no response, the duration was 1,000 ms. The next trial began after a 1,000-ms intertrial interval, during which the screen was blank.
The participant was asked to fixate on the central cross throughout each trial, and in the target-detection task, he/she was required to press the space bar on a computer keyboard as rapidly as possible whenever he/she detected the target. A 500-ms feedback beep was presented if the participant made a response to a catch trial that contained no target. In the object detection task, the participant was asked to press the space bar whenever he/she detected the rectangles. Accuracy was measured and no feedback was provided in the object detection task.
Results
Awareness manipulation check
Regarding the answer to the open question, all participants reported that they were unable to perceive any figures aside from the cue, target, fixation, and Mondrians during the entire unaware block. On the other hand, all participants reported seeing the rectangles during the aware block. For the object detection task, the mean detection rate on the object trials in the unaware block was as low as that on the no-object trials (p > .5), whereas it was 96.25% in the aware block, which was significantly higher than the detection rate on the no-object trials (p < .0001) (Fig. 4). According to both measures, the awareness manipulation of rectangles in this study is reliable.

Mean response times as a function of awareness state (aware, unaware) under each condition. Error bars represent one standard error from the mean. The number shown in each bar denotes the percent error of each condition. a The mean detection rate of the unaware trials is equal to that of the no-object trials (p > .5)
Target detection task
The mean correct RTs on object trials were submitted to a two-way analysis of variance (ANOVA) with the within-subjects factors of awareness state (aware, unaware) and validity (valid, IS, ID). The main effect of validity was significant, F (2, 38) = 16.16, p < .001. However, the main effect of awareness state and the interaction of validity and awareness state were far from statistically significant, F (1, 19) = 0.008, p = .93; F (2, 38) = 0.054, p = .94. There were no differences in error rates across conditions, indicating no speed–accuracy trade-off.
Pairwise comparisons showed shorter RTs for valid than for IS and ID trials (ps < .05), replicating the finding that a spatial cue can capture participants’ attention to the cued location (Egly et al., 1994). More important, the spatial cue led to the same-object advantage regardless of participants’ awareness of the objects: Shorter RTs were found when the target appeared at the cued object (IS) than at the uncued object (ID) (p < .05), with comparable magnitudes of the same-object-advantage in the aware and unaware blocks. The magnitudes of the same-object advantage in both blocks—24 and 23 ms, respectively (ps < .05 for planned t-tests)—are consistent with the range of such effects reported in the literature (e.g., Moore, Yantis, & Vaughan, 1998; Shomstein & Behrmann, 2008).
The data from the no-object trials (see Table 1) were also submitted to a two-way ANOVA with the factors of awareness state (aware, unaware) and validity (valid, IS, ID). The main effect of validity was significant, F (2, 38) = 3.27, p < .05. The main effect of awareness state and the interaction of validity and awareness state were, again, far from statistically significant, F (1, 19) = 0.001, p = .99; F (2, 38) = 0.61, p = .55. There were no differences in error rates across conditions, indicating no speed–accuracy trade-off. Pairwise comparisons showed shorter RTs for valid than for IS and ID trials (ps < .05), proving that the spatial cue in this study could capture participants’ attention to the cued location. More important, data from the no-object trials did not show any significant difference between the IS and ID conditions (p = .62). That is, there was no same-object advantage on the no-object trials.
Discussion
By adopting the CFS technique with the two-rectangle method, we found a significant same-object advantage, regardless of whether the participants were aware or unaware of the objects. We confirmed the consciousness state of the aware and unaware groups by both measures of the open question and the object detection task. Furthermore, the same-object advantage obtained was indeed caused by the objects and cannot be attributed to other confounding factors—for example, hemifield of target, expectation, and other strategies—because we used horizontal rectangles, and when we analyzed the results from the no-object trials, there were no differences in performance between the IS and ID conditions in both blocks.
To our knowledge, almost all evidence supporting object-based attention has been obtained from studies using objects where participants were fully aware of their existence (e.g., Baylis & Driver, 1993; Duncan, 1984; Egly et al., 1994). The fact that both aware and unaware blocks led to similar same-object advantages in the present study provides evidence for object-based attention under the unconscious state—just as was observed under the conscious state. In other words, consciousness of the object is not required for object-based attention, and the consciously and unconsciously perceived object may trigger the same attentional processing, making attention either shift faster within the cued object (Egly et al., 1994) or spread throughout the whole cued object, as compared with the uncued object. Abrams and Law (2002) showed that when random noises were added to the two-rectangle display, the same-object advantage disappeared even when the noises did not eliminate participants’ awareness of the objects. Taking their results along with the present one leads to the conclusion that awareness of the objects is neither necessary nor sufficient for object-based attention.
Showing that object-based attention can occur even when observers are unaware of the objects is inconsistent with the results of Ariga et al. (2007, Experiment 2). The fact that Ariga et al. used illusory objects, presented the cue before the appearance of the objects, and provided no object preview time before the appearance of the target may have weakened the strength of object representation, thereby weakening the ability of unconsciously processed objects to guide attention. In contrast, our use of real-contour objects, presenting the objects before the cue, and providing 1,900-ms object preview time may have strengthened the object representation; thus, selection based on an unconscious object is possible.
In addition to the methodological concern, within the mainstream of recent debate as to the issue of whether attention and consciousness are independent (Koch & Tsuchiya, 2006) or whether attention is necessary for consciousness (Mack & Rock, 1998; Simons & Levin, 1997), the opposite stand as suggested by Ariga et al. (2007)—awareness is necessary for attention—would be unusual, had it not been applied to objects (as opposed to locations) as selection units. Although the present study was not designed to clarify this debate, we did demonstrate that awareness of an object is not the gate of object-based attention and provided counterevidence to the latter position. Additionally, our finding is consistent with those of previous studies and suggests that stimuli suppressed from consciousness are not suppressed from further processing (e.g., He, Cavanagh, & Intriligator, 1996; Jiang et al., 2006; Lo & Yeh, 2008; Moore et al., 1998; Ortells, Vellido, Daza, & Noguera, 2006).
Both the mainstream theoretical framework (e.g., Treisman & Gelade, 1980) and empirical evidence (e.g., Jiang et al., 2006; Mulckhuyse et al., 2007) indicate that a subliminal stimulus can capture attention to a specific location for future processing. In the present study, we extended this argument to object-based attention: Attention can “select” an object even when we are not conscious of it. The ability of object-based attentional guidance by an unconscious object seems to have an ecological function: Although there are many unconscious objects in our visual world, they do modulate our visual attention in both a location- and an object-based manner to facilitate processing.
We propose that the attentional guidance from unconscious objects may play a fundamental role in much high-level unconscious processing—for example, the gist of a scene (Li, VanRullen, Koch, & Perona, 2002), the semantic meaning of a word (Naccache, Blandin, & Dehaene, 2002; Y. H. Yang & Yeh, 2011; Yeh, He, & Cavanagh, in press), the emotion on a face (E. Yang, Zald, & Blake, 2007), and the category of an object (Almeida, Mahon, Nakayama, & Caramazza, 2008): All of these unconscious processes imply implicit object recognition at different levels. Regardless of the awareness state, visual processing initially breaks up the visual scene into isolated fragments that are detected by individual neurons in the primary visual cortex and higher visual areas (Livingstone & Hubel, 1988). Visual perception of objects somehow reassembles the isolated fragments into complete objects. The problem of creating a unified percept from the responses of separate neurons is referred to as the “binding problem” (Treisman, 1996), and our finding here suggests that unconscious objects face the same binding problem as do conscious objects. In line with the unconscious binding hypothesis, which states that the unconscious mind not only encodes individual features, but also binds features (Lin & He, 2009), we propose further that attentional guidance by unconscious objects may be the mechanism for unconscious binding of features. This speculation bears some similarities to the main concept of the feature integration theory (Treisman & Gelade, 1980) that attention integrates separate features at the master map of location. Here, we demonstrate that unconscious objects also can be the interface for integration. We suggest that attention not only plays the critical role in feature integration in conscious vision, but also integrates individual features that belong to an invisible object in unconscious vision.
References
Abrams, R. A., & Law, M. B. (2002). Random visual noise impairs object-based attention. Experimental Brain Research, 142, 349–353.
Almeida, J., Mahon, B. Z., Nakayama, K., & Caramazza, A. (2008). Unconscious processing dissociates along categorical lines. Proceedings of the National Academy of Sciences, 105, 15214–15218.
Ariga, A., Yokosawa, K., & Ogawa, H. (2007). Object-based attentional selection and awareness of object. Visual Cognition, 15, 685–709.
Bahrami, B., Lavie, N., & Rees, G. (2007). Attentional load modulates responses of human primary visual cortex to invisible stimuli. Current Biology, 17, 509–513.
Baylis, G. C., & Driver, J. (1993). Visual attention and objects: Evidence for hierarchical coding of location. Journal of Experimental Psychology: Human Perception and Performance, 19, 451–470.
Davis, G., & Holmes, A. (2005). Reversal of object-based benefits in visual attention. Visual Cognition, 12, 817–846.
Duncan, J. (1984). Selective attention and the organization of visual information. Journal of Experimental Psychology: General, 113, 501–517.
Egly, R., Driver, J., & Rafal, R. D. (1994). Shifting visual attention between objects and locations: Evidence from normal and parietal lesion subjects. Journal of Experimental Psychology: General, 123, 161–176.
He, S., Cavanagh, P., & Intriligator, J. (1996). Attentional resolution and the locus of visual awareness. Nature, 383, 334–337.
Jiang, Y., Costello, P., Fang, F., Huang, M., & He, S. (2006). A gender- and sexual orientation-dependent spatial attentional effect of invisible images. Proceedings of the National Academy of Sciences, 103, 17048–17052.
Koch, C., & Tsuchiya, N. (2006). Attention and consciousness: Two distinct brain processes. Trends in Cognitive Sciences, 11, 16–22.
Li, F. F., VanRullen, R., Koch, C., & Perona, P. (2002). Rapid natural scene categorization in the near absence of attention. Proceedings of the National Academy of Sciences, 99, 8378–8383.
Lin, Z., & He, S. (2009). Seeing the invisible: The scope and limits of unconscious processing in binocular rivalry. Progress in Neurobiology, 87, 195–211.
Livingstone, M., & Hubel, D. (1988). Segregation of form, colour, movement, and depth: Anatomy, physiology, and perception. Science, 240, 740–749.
Lo, S. Y., & Yeh, S.-L. (2008). Dissociation of processing time and awareness by the inattentional blindness paradigm. Consciousness & Cognition, 17, 1169–1180.
Mack, A., & Rock, I. (1998). Inattentional blindness. Cambridge, MA: MIT Press.
Moore, C. M., Yantis, S., & Vaughan, B. (1998). Object-based visual selection: Evidence from perceptual completion. Psychological Science, 9, 104–110.
Mulckhuyse, M., Talsma, D., & Theeuwes, J. (2007). Grabbing attention without knowing: Automatic capture of attention by subliminal spatial cues. Visual Cognition, 15, 779–788.
Naccache, L., Blandin, E., & Dehaene, S. (2002). Unconscious masked priming depends on temporal attention. Psychological Science, 13, 416–424.
Ortells, J. J., Vellido, C. M., Daza, T., & Noguera, C. (2006). Semantic priming effects with and without perceptual awareness. Psicológica, 27, 225–242.
Posner, M. I. (1980). Orienting in attention. Quarterly Journal of Experimental Psychology, 32, 3–25.
Shomstein, S., & Behrmann, M. (2008). Object-based attention: Strength of object representation and attentional guidance. Perception & Psychophysics, 70, 132–144.
Simons, D. J., & Levin, D. T. (1997). Change blindness. Trends in Cognitive Sciences, 1, 261–267.
Treisman, A. (1996). The binding problem. Current Opinion in Neurobiology, 6, 171–178.
Treisman, A., & Gelade, G. (1980). A feature-integration theory of attention. Cognitive Psychology, 12, 97–136.
Tsuchiya, N., & Koch, C. (2005). Continuous flash suppression reduces negative afterimages. Nature Neuroscience, 8, 1096–1101.
Vecera, S. P., & Farah, M. J. (1994). Does visual attention select objects or locations? Journal of Experimental Psychology: General, 123, 146–160.
Yang, E., Zald, D. H., & Blake, R. (2007). Fearful expressions gain preferential access to awareness during continuous flash suppression. Emotion, 7, 882–886.
Yang, Y. H., & Yeh, S.-L. (2011). Accessing the meaning of invisible words. Consciousness and Cognition, 20, 223–233.
Yeh, S.-L., He, S., & Cavanagh, P. (in press). Semantic priming from crowded words. Psychological Science.
Author Note
This research was supported by Taiwan’s National Science Council (NSC 96-2413-H-002-009-MY3 and NSC 98-2410-H-002-023-MY3).
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article
Cite this article
Chou, WL., Yeh, SL. Object-based attention occurs regardless of object awareness. Psychon Bull Rev 19, 225–231 (2012). https://doi.org/10.3758/s13423-011-0207-5
Published:
Issue Date:
DOI: https://doi.org/10.3758/s13423-011-0207-5